



Introducción
El diccionario de epidemiología define al sesgo de publicación como «una predilección editorial para publicar hallazgos particulares, por ejemplo, resultados positivos, lo que lleva a los autores a no enviar resultados negativos para ser publicados»1. Esta definición asume que el error recae en los investigadores y no en los equipos editoriales de las revistas, lo que no se ha comprobado. Una definición más realista es que el sesgo de publicación se produce cuando lo que se publica no representa el total de las investigaciones realizadas acerca de un tema. Si lo que se publica no representa lo que se investiga se está distorsionando todo el proceso de aprendizaje y progreso en un tema. Aquí radica la importancia del sesgo de publicación.
La conciencia de sesgo de publicación comenzó en 1956 cuando el director de la revista Journal of Abnormal Social Psychology señaló que los estudios negativos tenían menos probabilidades de publicarse en su revista2. En 1959, en 4 revistas de psicología, se observó que se publicaban muy pocos resultados negativos, un hallazgo que sugirió la presencia de sesgo de publicación3; sin embargo, la cuantificación del problema no se consideró hasta 19644.
El sesgo de publicación siempre tiene importancia, pero donde más puede manifestarse es en el campo de la revisión sistemática, en la medida en que puede significar que las conclusiones alcanzadas pueden ser erróneas. Hay revisiones en castellano de los factores que influyen en el sesgo de publicación5. En la exposición de esta revisión se contestarán a las preguntas: ¿se debe valorar su presencia?, ¿cómo puede valorarse? y ¿qué aspectos hay que tener en cuenta en su valoración?
¿Se debe valorar la posible presencia del sesgo de publicación?
La presencia del sesgo de publicación constituye una amenaza potencial para la validez de las conclusiones de una revisión sistemática. Por ello, en principio debiera valorarse siempre. Puede haber un sesgo de publicación a pesar de una búsqueda bibliográfica hecha con rigor. Los protocolos QUOROM6 y MOOSE7 lo incluyen entre los aspectos que debe considerar todo metaanálisis que aspire a ser publicado. Se entiende que toda revisión sistemática no acaba necesariamente en metaanálisis (síntesis estadística de diferentes estudios), y el sesgo de publicación requiere, como se verá en el apartado siguiente, que haya metaanálisis. A pesar de esta recomendación, la valoración del sesgo de publicación es infrecuente en los metaanálisis publicados, como así lo atestigua una reciente valoración8 que encontró que la frecuencia de valoración en una serie de metaanálisis publicados en un período de 13 años era del 10%, aunque iba aumentando con el tiempo. La frecuencia era menor en los trabajos aparecidos en la Cochrane Library. La razón de ello puede estribar en que el protocolo Cochrane intenta localizar rutinariamente estudios no publicados. Pero como se comprobó hace algunos años9, en una encuesta a 42.000 obstetras y pediatras de todo el mundo para documentar todos los ensayos clínicos en curso en perinatología, es imposible identificar todos los estudios en ese campo (y este resultado se puede extender a otros terrenos). Por lo tanto, una búsqueda exhaustiva de estudios, incluyendo estrategias para la identificación de estudios no publicados, no puede garantizar que el sesgo no esté presente y, por ello, no se debe obviar su valoración.
¿Cómo valorar la presencia del sesgo de publicación?
Es un problema no resuelto en el que se deben esperar avances en los próximos años. Los métodos deben basarse en asunciones estadísticas, que se derivan en realidad de los factores que influyen en la presencia de este sesgo. Hasta el momento se han identificado diferentes variables que influyen en la presencia del sesgo de publicación, como la financiación10, el conflicto de intereses11, el prejuicio12, el prestigio de la institución13, el idioma14, etc., pero 2 son los factores que más claramente se han relacionado y que guardan una estrecha relación entre ellos: la significación estadística10-13 y el tamaño de la muestra10,13. Los procedimientos que hay para detectar el sesgo de publicación se basan esencialmente en estas 2 variables. A continuación se mencionan los métodos más empleados en la literatura científica, según una valoración en una serie de revisiones sistemáticas8.
Gráficos en embudo y árboles de navidad
El gráfico en embudo es cronológicamente el primero en aparecer y es, con diferencia, el más utilizado. Al principio se representó en el eje de abscisas el tamaño de muestra y en el de ordenadas el parámetro de cada estudio (riesgo relativo [RR], odds ratio [OR], diferencia de medias, etc.) que mide la magnitud de la asociación entre una exposición y un efecto15. Se obtiene así un embudo que se estrecha hacia la derecha, ya que los estudios con mayor tamaño de muestra suelen tener menor variabilidad entre ellos. La presencia de una figura simétrica alrededor de un eje horizontal que pase por el valor ponderado del parámetro indica la ausencia de este error. Con posterioridad en el eje de las abscisas se representó el error estándar (EE) del parámetro, en vez del tamaño de muestra16; en este formato, el embudo se estrecha hacia la izquierda ya que los estudios con mayor precisión (menor EE, equivalente a un mayor tamaño de muestra) se sitúan en el lado izquierdo de la figura.
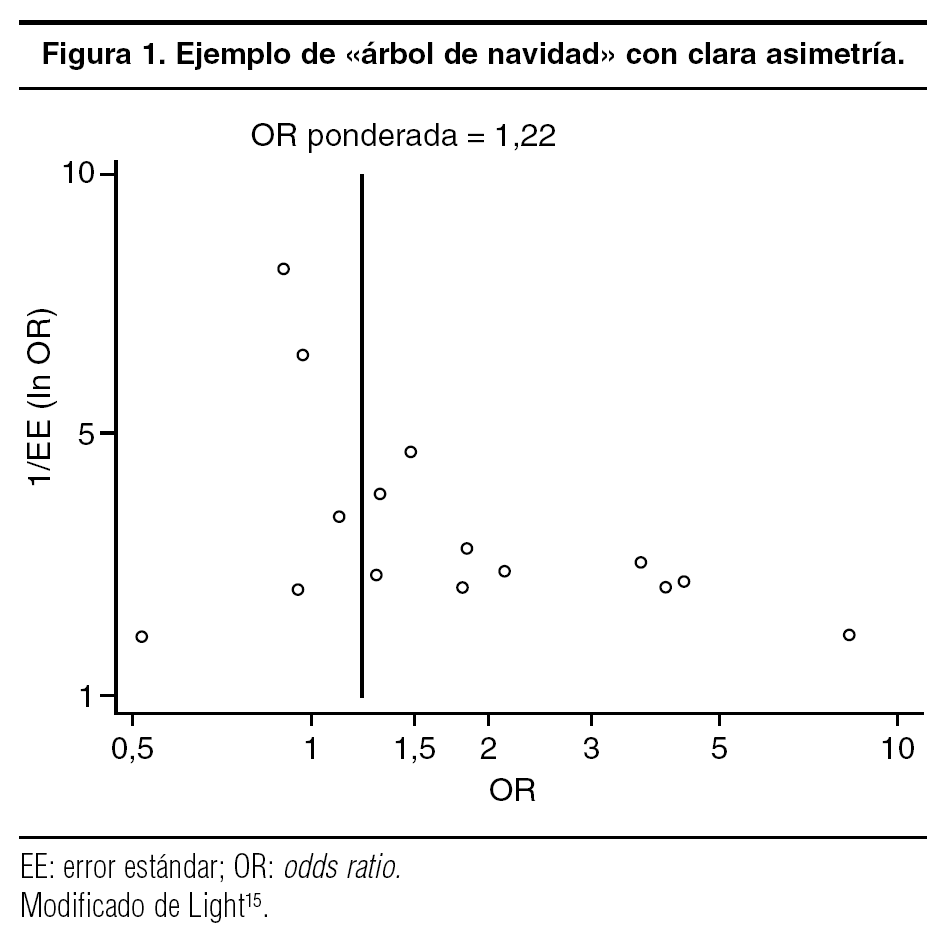
El intercambio de los ejes del gráfico en embudo da origen al gráfico conocido como «árbol de navidad» («Christmas tree»), en el que en el eje de ordenadas se coloca el tamaño de muestra y en el eje de abscisas la magnitud del efecto. Si se utiliza el EE, se calcula el inverso de éste (= precisión), para que el árbol sea más ancho por la parte inferior del gráfico. En estas situaciones se traza un eje vertical que pasa por la estimación ponderada y se valora la simetría alrededor del eje. Un ejemplo de ello se muestra en la figura 1, en la que se aprecia con claridad que los estudios pequeños tienden a mostrar asociaciones fuertes, mientras que los 2 estudios con mayor precisión dan valores próximos a la unidad. En este metaanálisis17, que relaciona la presencia de un polimorfismo en el gen de la enzima de conversión de la angiotensina con la reestenosis coronaria, el resultado global según un modelo de efectos fijos fue de una OR = 1,22 (intervalo de confianza [IC] del 95%, 1,07-1,40).
Los gráficos en embudo presentan la ventaja de que se pueden realizar con los datos publicados. Su principal desventaja consiste en que la simetría se define de manera subjetiva por el investigador18. Las representaciones gráficas de este tipo se pueden hacer con facilidad con cualquier programa de gráficos.
Trim and fill
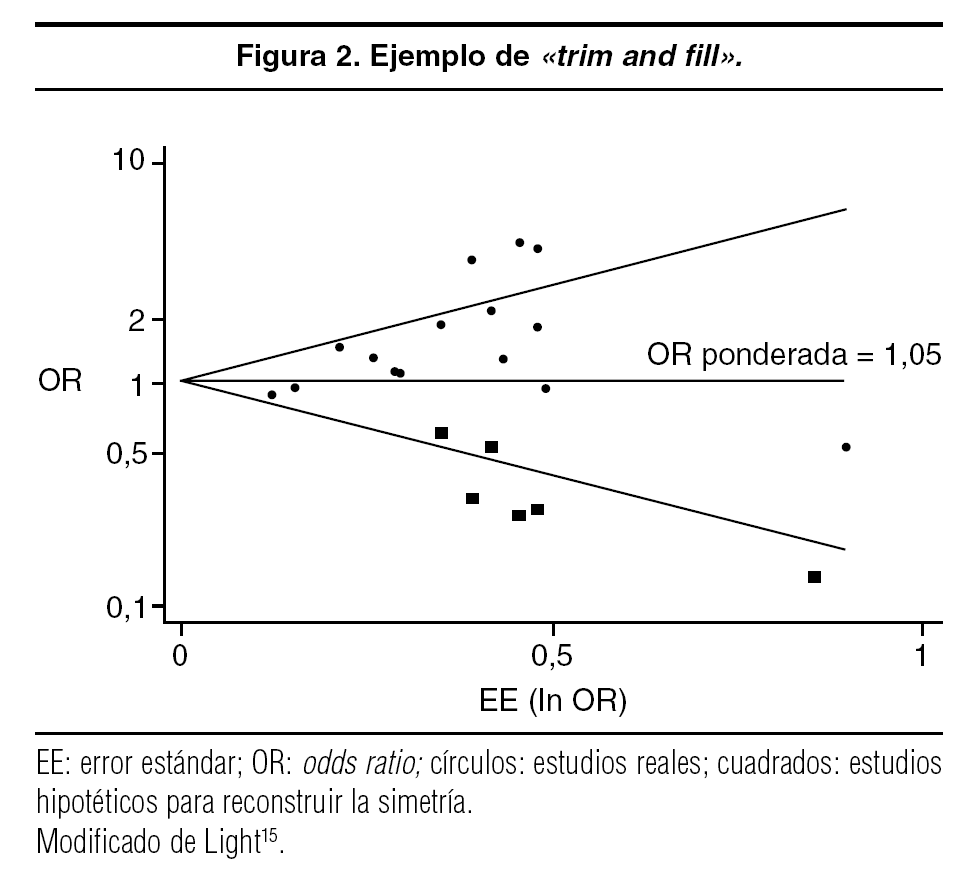
Tiene una traducción difícil («podar y completar»), por eso se ha respetado su denominación anglosajona. Este método se deriva del gráfico en embudo19. En primer lugar, se calcula una media ponderada con todos los estudios. Mediante un sencillo algoritmo se determina la porción del gráfico que contiene los estudios simétricos, se eliminan los restantes (asimétricos) y se calcula una nueva media ponderada. Con posterioridad, se determinan cuáles debían ser los estudios que faltaban en la parte asimétrica, que unidos a los detectados en este mismo sector, conducirían a un valor medio ponderado idéntico al obtenido con la parte simétrica. En realidad, de lo que se trata es de reconstruir una imagen especular idéntica alrededor de un eje que pasa por el valor medio ponderado obtenido con la parte simétrica de la tabla. Una vez que se obtiene la imagen especular con los estudios añadidos (con un peso similar al que tienen su reflejo al otro lado del eje), se recalcula la media ponderada y su varianza. En el programa STATA hay un comando que permite estimarlo sin dificultad, llamado metatrim (este comando para los usuarios registrados de STATA se puede bajar gratuitamente de la web http://www.stata.com). En la figura 2 se representa el mismo metaanálisis de la figura 1, pero se identifican 6 nuevos estudios que son necesarios para que el gráfico en embudo sea simétrico (representados cada uno con un cuadrado). La adición de estos nuevos estudios a los 16 originales ocasiona que la OR ponderada no sea ya estadísticamente significativa (OR = 1,05; IC del 95%, 0,93-1,19). La diferencia con el gráfico en embudo, del que deriva, es que permite de manera aproximada medir el impacto del sesgo de publicación20.

Figura 1. Ejemplo de «árbol de navidad» con clara asimetría.

Figura 2. Ejemplo de «trim and fill».
Método de Begg
Utiliza el coeficiente de correlación ordinal tau de Kendall entre la medida estandarizada de magnitud de asociación, ya sea con su varianza21 o con el tamaño de muestra22. Este procedimiento no se recomienda, porque los estudios de simulación realizados comprueban que es inferior (tiene menor sensibilidad y especificidad) a los 2 procedimientos que a continuación se detallan23-25.
Método de Egger
Se deriva del método de Galbraith26. Se realiza un análisis de regresión lineal simple entre el valor z de cada estudio (si es el RR, z = ln RR/EE[ln RR]) como variable dependiente, y su precisión, medida por el inverso del EE (si es el RR, EE[ln RR]), como variable independiente27. La regresión se puede estimar ponderando por el inverso de la varianza o sin ponderar, pero los propugnadores del método la recomiendan ponderada.
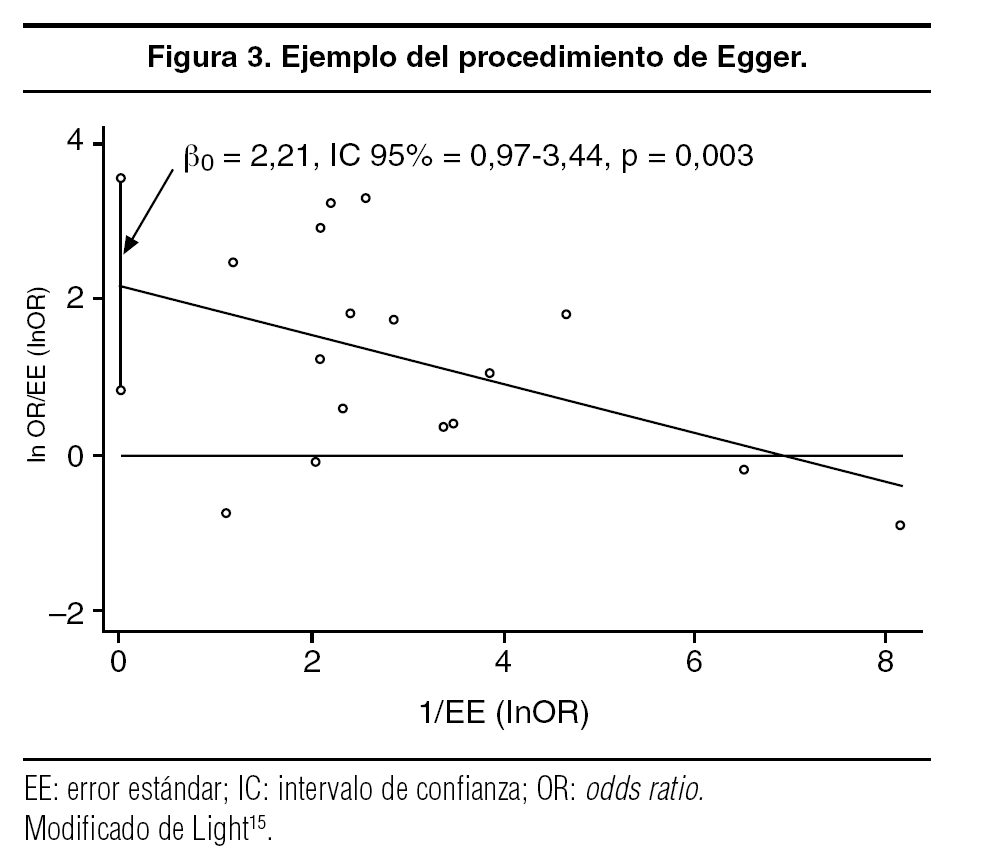
En ausencia de sesgo, los estudios pequeños tendrán poca precisión al tener un error estándar grande (cerca del eje de las ordenadas), y por esta misma razón su valor z será pequeño; es decir, estarán próximos a las coordenadas 0,0 de la figura. Al realizar un análisis de regresión lineal forzarán que la recta pase por el valor 0 del eje de ordenadas (ordenada en el origen, β0 = 0). Por el contrario, si los estudios pequeños tienden a publicarse cuando sus resultados son significativos provocarán que la recta de regresión cruce al eje de ordenadas en un punto alejado de 0: positivo si la asociación es positiva y negativo si es protectora. Por lo tanto, es la ordenada en el origen la que indica la presencia del sesgo de publicación. Cualquier programa estadístico permite realizar este tipo de análisis y ofrece una prueba de significación estadística de que β0 ≠ 0. El valor de p que se suele utilizar para sugerir la presencia de sesgo es < 0,1 y no < 0,05.
Los autores del procedimiento recomiendan que la regresión se haga ponderando por el inverso de la varianza, pero las simulaciones realizadas por Macaskill et al23 muestran que funciona mejor el procedimiento sin ponderar, con una mayor sensibilidad para detectar la presencia del sesgo de publicación. Este resultado parece lógico en la medida en que un análisis ponderado por el inverso de la varianza resta importancia a los estudios pequeños frente a los grandes, y son los primeros los que marcan la ordenada en el origen. En la figura 3 se aplica este procedimiento al mismo metaanálisis de figuras anteriores. Es de notar que los estudios pequeños tienden a mostrar valores significativos en la asociación (z > 1,96), mientras que los grandes no, lo que causa que la pendiente de la recta sea negativa y que la ordenada en el origen sea claramente distinta de 0. La gráfica se ha construido con el comando metabias del paquete STATA (este comando para los usuarios registrados de STATA se puede bajar gratuitamente de la web http://www.stata.com), pero puede construirse sin problemas con cualquier otro programa de gráficos. La ventaja del comando de STATA es que proporciona el IC de β0 sin esfuerzos adicionales.

Figura 3. Ejemplo del procedimiento de Egger.
Regresión sobre el gráfico en embudo
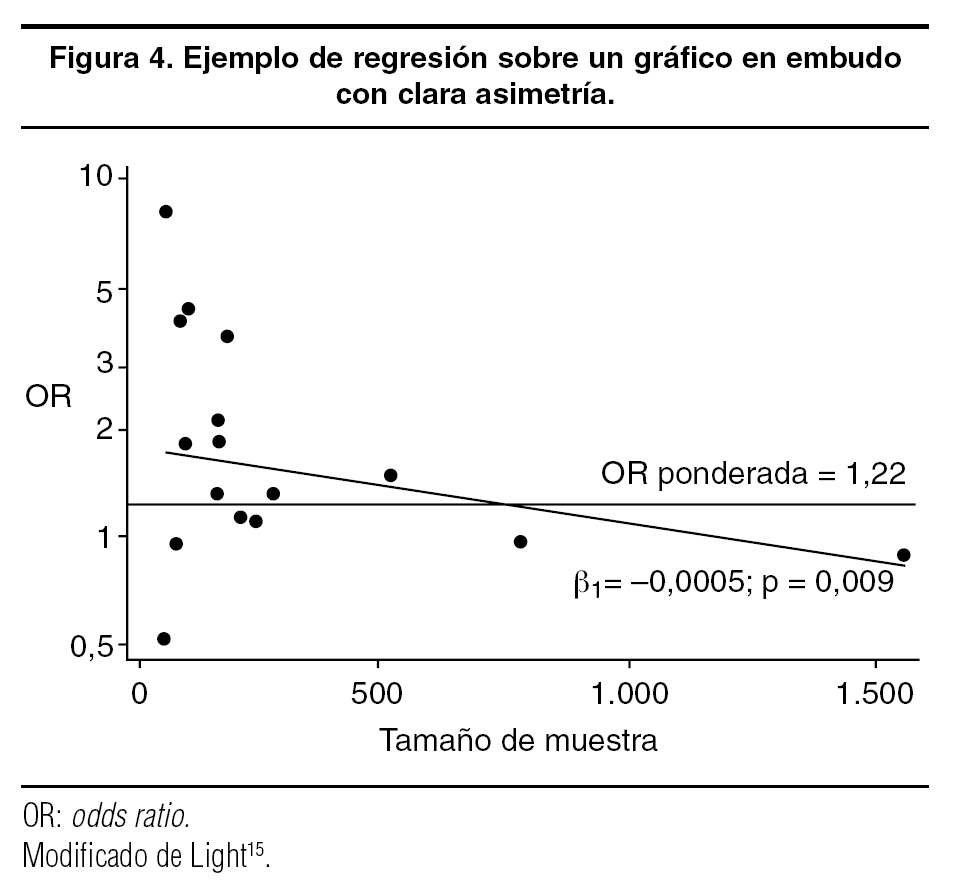
Macaskill et al23 proponen realizar una regresión lineal simple en el clásico gráfico en embudo15, entre la magnitud del efecto (variable dependiente) y el tamaño del estudio (variable independiente). Los autores recomiendan que la regresión se haga ponderando, ya sea por el inverso de la varianza de la magnitud de la asociación (p. ej., 1/Var[ln RR]) o por el inverso de la varianza de la incidencia del efecto en el total de la población de cada estudio. En este procedimiento, lo que se investiga es si la pendiente de la recta de regresión, b1, es distinta de 0 o no. Cuando es próxima a 0 y el análisis de regresión da un valor p no significativo, indica que no hay sesgo de publicación. Una pendiente = 0 sugiere que la influencia de los estudios por encima del valor ponderado es similar a la de los estudios por debajo de este valor para los diferentes tamaños de muestra, es decir, que la imagen es razonablemente simétrica. Un ejemplo de este método se aprecia en la figura 4, con el mismo metaanálisis de figuras anteriores. Se aprecia en el gráfico en embudo la clara asimetría alrededor del valor ponderado de la OR, los estudios pequeños tienen una tendencia a mostrar valores de OR claramente por encima de 1, mientras que los grandes no. Esto inclina la recta y la pendiente es negativa (p = 0,009 de ser distinta de 0).

Figura 4. Ejemplo de regresión sobre un gráfico en embudo con clara asimetría.
Este método es más específico que los métodos de Begg y Egger, da muchos menos falsos positivos que los otros métodos. La dificultad que presenta es que es menos sensible que los otros para detectar sesgo de publicación. Se ha sugerido una modificación al método de Macaskill cuando el parámetro que se pondera es la OR, usar como variable independiente el inverso del tamaño de muestra total. Tiene la misma potencia estadística que el método de Egger, pero la frecuencia de falsos positivos (error alfa) es mucho menor28.
Los procedimientos descritos tienen la ventaja de que se pueden calcular tan sólo con los datos publicados: no requieren asumir distribuciones, ni otros factores, de los estudios no publicados. Hay otros procedimientos que se usan excepcionalmente y por esta razón no se detallarán. Hay métodos que estiman el número de estudios publicados29-31, remuestreo o muestreos truncados32,33, basados en la teoría de distribución de pesos21,34, métodos de captura-recaptura35, procedimientos de máxima verosimilitud36, bayesianos37, etc. Las ventajas e inconvenientes de algunos de ellos se resumen en la revisión de Thornton y Lee18. Recientemente se ha desarrollado un método para valorar el sesgo de publicación cuando los datos binarios son escasos, merced a una correlación por rangos entre los valores observados y esperados de las casillas, pero aún no hay experiencia práctica sobre él38.
¿Qué aspectos hay que tener en cuenta en la valoración de los métodos para detectar sesgo de publicación?
En primer lugar, hay que tener en cuenta el número de estudios. Los métodos de detección del sesgo de publicación son poco fiables cuando el número de estudios es pequeño, por debajo de 10. Los procedimientos de simulación denotan que los falsos negativos y falsos positivos de los métodos de regresión son muy frecuentes en esta situación23-25. El problema es aún mayor con el gráfico en embudo, es muy difícil juzgar la simetría de una imagen cuando el número de puntos es reducido, y no obstante, se pueden encontrar gráficos en embudo con tan sólo 3 estudios39.
El segundo de los grandes inconvenientes en la interpretación del sesgo de publicación viene motivado por la presencia de heterogeneidad en el metaanálisis. La heterogeneidad es la constatación de que entre los estudios que se combinan hay diferencias estadísticamente significativas. Un problema añadido es que las pruebas para detectar heterogeneidad no son muy sensibles, y por ello se sitúa el corte en el valor p en 0,1. Lo anterior se traduce en que puede haber heterogeneidad real en un metaanálisis, no detectarla, e interferir con la valoración del sesgo de publicación. A ello hay que sumar el que las pruebas de heterogeneidad difieren mucho si se aplica un modelo de efectos fijos (que sólo asume variabilidad intraestudio) o un modelo de efectos aleatorios (que asume además variabilidad entre los estudios). Con gran frecuencia, el modelo de efectos aleatorios produce resultados en las pruebas de heterogeneidad mucho menos significativos que los de los modelos de efectos fijos. Esto es, los investigadores pueden combinar varios estudios con un modelo de efectos aleatorios, como estrategia para obviar una heterogeneidad existente; si en esta situación el resultado de un método de valoración del sesgo de publicación es positivo, habrá que interpretarlo con mucha precaución, ya que la heterogeneidad se ha suprimido por la elección del modelo de análisis, no porque en realidad haya desaparecido.
Si se quiere valorar la repercusión del sesgo de publicación en el resultado final del metaanálisis, esto es, si se alteran las conclusiones sacadas del análisis, el único procedimiento fácil de implementar en la actualidad es el trim and fill. Hay situaciones en las que el sesgo es claro, como sucede en el clásico metaanálisis acerca de la estreptocinasa intravenosa y la mortalidad postinfarto de miocardio40. Éste es un metaanálisis en el que se sintetizaron 33 ensayos controlados publicados entre 1959 y 1988; 9 de los 14 estudios con menos 100 pacientes encontraron una OR < 0,5, frente a 2 de los 19 con 100 o más pacientes. A pesar de esta diferencia importante, el peso de los estudios multicéntricos GISSI-I (estudio con 11.712 pacientes) e ISIS-2 (con 17.187 pacientes) es tan grande, suponen el 78% de todos los pacientes aleatorizados en los 33 estudios, que la adición de estudios pequeños no tiene apenas repercusión y la OR ponderada fue de 0,83.
Con frecuencia, los distintos procedimientos comentados no coinciden. Esto es algo que se deduce de los pocos estudios de simulación que hay acerca del sesgo de publicación23,25. Nosotros, en una serie de 225 metaanálisis acerca de enfermedad cardiovascular que permitían reproducir el análisis de los autores, hemos comprobado que la concordancia es baja, con índices kappa normalmente < 0,441. Este hallazgo no tiene el rigor de una simulación, pero tiene el valor de la muestra empírica. Lo que se deduce de este resultado, en todo caso, es que se debe aplicar más de un procedimiento para valorar el sesgo de publicación. Cuando son coincidentes, en ausencia de las limitaciones anteriores, la probabilidad de que el sesgo esté presente es mayor. En el caso de no concordancia entre ellos, el evaluador debe juzgar cuál debe ser su conclusión; si un trim and fill no cambia el valor de la conclusión, debería reflejarse. No se puede avanzar más en este momento en este punto.
Los procedimientos de valoración del sesgo de publicación no son perfectos porque las asunciones sobre las que se basan tan sólo tienen en cuenta aspectos parciales de los determinantes del sesgo. Un sesgo sólo puede identificarse, y a ser posible neutralizarse, si se conocen todos los factores que influyen en su presencia. Es demasiado simplista reducirlo todo a tamaño de muestra o significación estadística. Se han documentado varios aspectos que matizan entre significación estadística y publicación: los resultados significativos aparecen antes que los no significativos42,43, los estudios aleatorizados son menos susceptibles a este problema que los no aleatorizados10, el carácter multicéntrico12, la financiación por parte de la industria farmacéutica44 y el idioma materno de los investigadores (los resultados significativos van con más frecuencia a revistas en inglés)14. Para mejorar la baja sensibilidad y especificidad que muestran los procedimientos habría que diseñar un método que tuviera en cuenta estas variables (carácter multicéntrico, aleatorización, financiación, etc.). Esto requiere asumir el grado de influencia o peso que tienen esas otras variables en la presencia del sesgo de publicación. A través de técnicas de análisis multivariable podría crearse un modelo que permitiera comprobar si el sesgo es probable. El problema es que lo anterior no es nada fácil; primero, porque no hay muchos estudios que hayan documentado la influencia que tienen y, segundo, porque el peso de éstas puede cambiar con la pregunta de investigación.
Hacer una serie de recomendaciones de lucha contra el sesgo de publicación es una tarea difícil y va más allá de las perspectivas de este trabajo. En la lucha contra el sesgo intervienen todos los elementos que influyen en la publicación, los autores, las revistas y los promotores de la investigación (que en ocasiones son propietarios de los datos). Todos deben ser conscientes que toda investigación correctamente realizada se debe publicar, pero el problema comienza cuando no todos (autores y revistas) están de acuerdo en lo que es una investigación «correcta» y en lo que puede ser un resultado de interés para ser publicado (lo que cambia el conocimiento existente). Esto último se ha puesto de manifiesto reiteradamente por la revisión sistemática, que encuentra con excesiva frecuencia resultados «llamativos» en las publicaciones.
En resumen, una de las principales amenazas del metaanálisis es el sesgo de publicación. Hay que valorarlo, a pesar de que las herramientas que se tengan son imperfectas y los resultados se deben interpretar teniendo en cuenta los factores que interfieren en su medición (el número de estudios y la heterogeneidad).
Correspondencia:
Miguel Delgado Rodríguez.
Área de Medicina Preventiva y Salud Pública.Edificio B-3. Universidad de Jaén.
23071 Jaén. España.
Correo electrónico: mdelgado@ujaen.es
Recibido: 16 de mayo de 2006. Aceptado: 14 de septiembre de 2006.











