





Presentar una metodología para optimizar, a través de la Z’-Score de Altman para empresas privadas, la predicción de entrada en situación de concurso de acreedores (bancarrota) en empresas privadas del sector sanitario español.
MétodoEl método propuesto consiste en la aplicación de los algoritmos genéticos (AG) para encontrar los coeficientes de la fórmula de la cadena de ratios propuestos por Altman en su versión para empresas privadas que optimicen la predicción en empresas privadas sanitarias españolas, maximizando la sensibilidad y la especificidad, y con ello reduciendo los errores de tipo I y tipo II. Con este propósito se ha utilizado una muestra de 5903 empresas del sector sanitario privado español obtenidas de las bases de datos de Sistema de Análisis de Balances Ibéricos (SABI) entre los años 2007 y 2015.
ResultadosEl modelo predictivo obtenido con los AG presenta mayor exactitud, sensibilidad y especificidad que el propuesto por Altman para empresas privadas, tanto con los datos de test como con todos los datos de la muestra.
ConclusionesEl hallazgo más importante del presente estudio es establecer una metodología que logra identificar unos coeficientes optimizados para la Z de Altman, lo cual permite realizar una predicción más precisa de la bancarrota en las empresas sanitarias privadas españolas.
This paper presents a methodology to optimize, using Altman's Z-Score for private companies, the prediction of private companies of the Spanish health sector entering a situation of bankruptcy.
MethodThe proposed method consists of the application of genetic algorithms (GA) to find the coefficients of the formula of the chain of ratios proposed by Altman in the version of the score for private companies which optimize the prediction for Spanish private health companies, maximizing sensitivity and specificity, and thereby reducing type I and type II errors. For this purpose, a sample of 5,903 companies from the Spanish private health sector obtained from the database of the Iberian Balance Analysis System (SABI) between 2007 and 2015 was used.
ResultsThe results show that the predictive model obtained with the AG presents greater accuracy, sensitivity and specificity than that proposed by Altman for private companies with both test data and all sample data.
ConclusionsThe most important finding of this study was to establish a methodology that can identify the optimized coefficients for the Altman Z-Score, which allows a more accurate prediction of bankruptcy in Spanish private healthcare companies.
La bancarrota es un evento crítico que puede causar grandes pérdidas a los prestamistas, accionistas, acreedores y naciones; por ello, el desarrollo de modelos de predicción de bancarrota ha sido uno de los principales temas de investigación en el área financiera1.
La literatura de la predicción de la bancarrota comienza en la década de 1930. FitzPatrick2, en 1932, comparó 13 ratios de empresas en bancarrota y no en bancarrota (activas) y descubrió que estas últimas poseían ratios más favorables. Hasta mediados de los años 1960, estas predicciones se basaban en un análisis univariable. El trabajo más reconocido fue el de Beaver3, quien encontró que un número determinado de ratios podían discriminar entre bancarrota y no bancarrota con hasta 5 años de antelación. En 1968, Edward Altman4 publicó el primer análisis multivariable. Este autor utilizó el análisis discriminante múltiple para desarrollar un modelo predictivo (denominado Z-Score) usando cinco ratios financieras para predecir la bancarrota de empresas manufactureras:
- 1)
(Activo circulante – Pasivo líquido) / Total activo.
- 2)
Reservas / Total activo.
- 3)
EBIT (Earnings Before Interest and Taxes) / Total activo.
- 4)
Capitalización bursátil /Deudas totales.
- 5)
Ingresos de explotación / Total activo.
Ohlson5 presentó una alternativa utilizando modelos logit, y Zmijewski6 usando modelos probit. En el año 2000, Altman7 adaptó su fórmula propuesta en 1968 para el sector de las empresas privadas, cambiando la variable Market value of equity (capitalización bursátil) por Book values of equity (patrimonio neto).
Por otro lado, hasta 1990, las técnicas estadísticas multivariables más usadas para la predicción de la bancarrota eran el análisis discriminante múltiple4,8, el logit5 y el probit6. Sin embargo, estas técnicas deben cumplir unos supuestos, como la linealidad, la normalidad y la independencia de las observaciones, que no siempre se cumplen en el ámbito financiero9. En consecuencia, dichos métodos pueden tener limitaciones de validez10.
Desde finales de los años 1980, las técnicas de inteligencia artificial, como las redes neuronales y los algoritmos genéticos (AG), han demostrado ser menos vulnerables a estas suposiciones11,12 y se han aplicado con éxito en la predicción de la bancarrota13,14. El primer artículo del uso de redes neuronales en la predicción de la bancarrota fue publicado en 1990 por Odom y Sharda15. En 2002, Shin y Lee10 utilizaron los AG para predecir la bancarrota. En la tabla I del Apéndice online se muestra un resumen de los principales autores en este campo.
Cabe mencionar que la predicción de la bancarrota ha sido utilizada en multitud de sectores y países (p. ej., en empresas manufactureras4 y no manufactureras7, en empresas de tamaño medio y pequeñas italianas16, y en empresas de Korea10). Sin embargo, no existe un modelo específico para el sector sanitario privado español. Por ello, este estudio propone la creación de un modelo ad hoc para predecir la salud financiera de estas empresas con 2 años de antelación17,18 utilizando la técnica de los AG y las cinco variables propuestas por Altman7 para las empresas privadas. De este modo, a través de los AG se calcularon unos nuevos coeficientes para las ratios que componen la Z’-Score de Altman adaptados a este sector (Z’-Score modificada), así como el nuevo punto de corte asociado a estos nuevos coeficientes para discriminar entre empresas en riesgo de problemas financieros y empresas sin riesgos.
La importancia de este sector en España es clara. Así, en el año 2015, el gasto de la sanidad española supuso el 9% del producto interior bruto19, del cual el 2,7% correspondió a la sanidad privada, siendo este dato superior respecto a otros países de nuestro entorno (1,7% en Alemania, 2,4% en Francia, 2,2% en Italia) (véase la tabla II del Apéndice online). También se puede observar cómo la colaboración entre el sector público y el privado va en aumento, y parece ser el camino que se pretende tomar en un futuro cercano20.
MétodoDatosLos datos se obtuvieron de la base de datos SABI (Sistema de Análisis de Balances Ibéricos)21. La muestra estuvo formada por aquellas empresas cuya última información disponible se encontraba entre los años 2007 y 2015. Debido a que se decidió realizar predicciones a 2 años, de todas las empresas se tomaron datos en dos cursos económicos diferentes. Del último año disponible se obtenía si la empresa estaba en concurso de acreedores o activa, y del año correspondiente a dos periodos anteriores al comentado se obtuvieron los datos contables necesarios para calcular las ratios propuestas por Altman8.
Los códigos CNAE (Clasificación Nacional de Actividades Económicas) utilizados para seleccionar las empresas del sector privado sanitario español fueron los siguientes: 2110, 2120, 3250, 4646, 4773, 4774, 7211, 7219, 7490, 8610, 8621, 8622, 8623 y 8690. De todas ellas, se seleccionaron las que tenían correctamente informadas las cinco ratios propuestas por Altman7 (véase formula 1). Finalmente, la muestra quedó conformada por 5824 empresas activas y 79 en concurso de acreedores. Estas cifras reflejan que la proporción de una categoría es extremadamente pequeña respecto a la otra. En estas situaciones, los modelos de clasificación tienden a predecir a la mayor parte de las empresas en la clase mayoritaria, de tal forma que se aumenta la exactitud a costa de ignorar a la clase minoritaria. Para resolver este problema de datos no balanceados se ha utilizado la técnica de inframuestrear la categoría mayoritaria, de modo que ambas categorías estén igualmente representadas22. En la tabla III del Apéndice online se muestra la estadística descriptiva de la muestra.
Técnica de los algoritmos genéticosLos AG simulan la teoría de la evolución propuesta por Darwin16. Fueron desarrollados por Holland23 y son procesos estocásticos robustos1,10 que pueden usarse para resolver problemas de búsqueda y optimización a través de una función fitness o función objetivo. Los AG realizan el proceso de búsqueda en cuatro pasos: inicialización, selección, cruce y mutación10.
En el proceso de inicialización, una población de individuos, llamados cromosomas, se distribuyen de forma aleatoria por el rango de búsqueda definido para cada coeficiente y son evaluados a través de la función fitness16.
En el proceso de selección, aquellos cromosomas que presenten valores más óptimos en la función fitness serán seleccionados para crear la siguiente generación16. En el proceso de cruce se seleccionan dos individuos con valores óptimos en la función fitness y se unen de manera que el descendiente contiene información parcial de cada uno de sus progenitores; de esta forma, cabe esperar que el descendiente mejore el resultado de la función fitness10.
La mutación es un mecanismo por el que de forma aleatoria se seleccionan miembros de la población y se cambia también aleatoriamente alguno de sus genes. De esta forma se desplazan valores numéricos hacia zonas del espacio de búsqueda que no pueden ser alcanzadas por los otros operadores genéticos10.
Análisis estadísticoPara solucionar el problema de los datos no balanceados se recurrió al procedimiento de validación cruzada dejando uno fuera, o leave-one-out cross-validation (LOOCV24). Esta técnica implica inframuestrear la categoría mayoritaria, seleccionando al azar el mismo número de empresas activas que de empresas en concurso de acreedores. Por ello, se parte de un conjunto de datos con 158 registros (79 empresas activas elegidas de forma aleatoria y 79 en concurso). Una vez definido el set de datos de entrenamiento con 157 registros y el de validación con un solo registro, al set de entrenamiento se le aplica la técnica de los AG, la cual devuelve diferentes soluciones, cada una de ellas formada con cinco coeficientes y un punto de corte (fig. 1). Por una parte, estas soluciones son acumuladas para obtener los coeficientes definitivos al final del proceso, y por otra parte se calculan las medias de cada coeficiente de estas soluciones, con lo que se obtienen cinco coeficientes y un punto de corte. Con este único resultado se procesa el set de validación y se construye la matriz de confusión. El mismo set es procesado utilizando la formula Z’-Altman para poder comparar los resultados obtenidos y determinar si el algoritmo propuesto los mejora (véase la tabla IV del Apéndice online, Fichero Test). El proceso se repite 158 veces, de tal modo que todos los registros son utilizados una vez como set validación.

Con el objetivo de obtener unos resultados robustos, este proceso se repite 100 veces, es decir, se crean 100 sets de datos, con 158 registros cada uno. Una vez terminado el proceso, se calculan las medias de los coeficientes de todas las soluciones acumuladas durante todo el proceso para obtener los coeficientes definitivos.
El programa estadístico utilizado fue R Core Team (2016)25, y se usaron los paquetes GA26, fmsb27 y pROC28.
Medidas de rendimientoLas medidas de rendimiento utilizadas se extraen a partir de una matriz de confusión22 (tabla 1), en la que los verdaderos positivos (VP) indican el número de empresas en concurso clasificadas correctamente. Los falsos negativos (FN) indican el número de empresas en concurso clasificadas erróneamente. Los verdaderos negativos (VN) indican el número de empresas activas clasificadas correctamente. Los falsos positivos (FP) indican el número de empresas activas clasificadas erróneamente.
La función fitness utilizada en los AG se ha definido como (0,30 * Sensibilidad + 0,70 * Especificidad), donde la sensibilidad29 representa la proporción de VP, VP / (VP + FN), y la especificidad es la proporción de VN, VN / (VN + FP). Así pues, se ha realizado una media ponderada entre la sensibilidad y la especificidad, de tal forma que el modelo tenga en cuenta los dos tipos de empresa, aportando más peso a la especificidad debido a la existencia de datos no balanceados.
También se han utilizado otras medidas, como: a) la exactitud (accuracy), VP + VN / (VP + FP + FN + VN), aunque presenta problemas cuando las clases no están equilibradas; b) la media geométrica (G-Mean), que se define como Sensibilidad*Especificidad, dando la misma importancia a la sensibilidad y a la especificidad30; c) el área bajo la curva ROC, que representa de forma gráfica el porcentaje de empresas activas clasificadas incorrectamente (1 − Especificidad) en el eje de abscisas y el porcentaje de empresas en concurso clasificadas correctamente (Sensibilidad)30, y cuando el área bajo esta curva tiene un valor 1, su máximo, implica que el modelo tiene un 100% de sensibilidad y de especificidad, con lo que la capacidad de discriminación del modelo es total, y así, cuanto mayor es su valor, mejor rendimiento tiene el modelo; d) el F1-Score, que representa la media armónica entre la sensibilidad y el valor predictivo positivo, VP / (VP + FP); y e) el coeficiente de correlación de Matthews (MCC) o coeficiente phi, que es una medida que puede utilizarse tanto en datos balanceados como no balanceados:
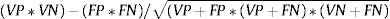
Una vez determinados los nuevos coeficientes y el nuevo punto de corte, se procedió a comparar el poder predictivo de ambos modelos. Para ello, se comparan los resultados obtenidos realizando predicciones con la Z’-Score modificada con los coeficientes calculados en el presente trabajo, con los resultados que se logran a través de la Z’-Score propuesta por Altman para empresas privadas7, la cual se detalla a continuación (la elección del trabajo de este autor se debió a que es uno de los más citados en relación a la predicción de la bancarrota31):
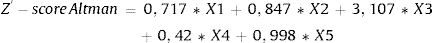
donde:
X1 = (Activo circulante – Pasivo líquido) / Total activo
X2 = Reservas / Total activo
X3 = EBIT / Total activo
X4 = Patrimonio neto / Deudas totales
X5 = Ingresos de explotación / Total activo
Para interpretar esta ratio se siguió el siguiente razonamiento. Si la puntuación Z’ obtenida resultaba inferior a 1,23, se encuadraba a la empresa en la categoría de «riesgo de bancarrota», y en caso contrario, en la de «no riesgo de bancarrota».
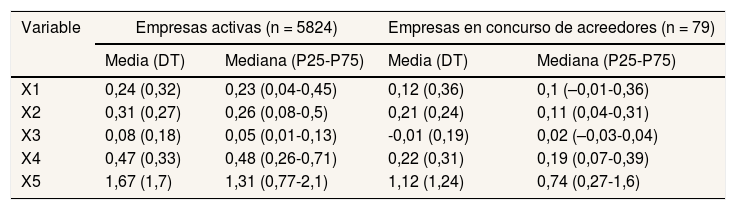
ResultadosEn primer lugar, se muestra la estadística descriptiva de los datos de la muestra desglosada por situación: «concurso de acreedores» o «activas». Se observa que las medias y las medianas son mayores en todas las ratios en las empresas activas (tabla 2).
Estadística descriptiva de los registros de la muestra
| Variable | Empresas activas (n = 5824) | Empresas en concurso de acreedores (n = 79) | ||
|---|---|---|---|---|
| Media (DT) | Mediana (P25-P75) | Media (DT) | Mediana (P25-P75) | |
| X1 | 0,24 (0,32) | 0,23 (0,04-0,45) | 0,12 (0,36) | 0,1 (–0,01-0,36) |
| X2 | 0,31 (0,27) | 0,26 (0,08-0,5) | 0,21 (0,24) | 0,11 (0,04-0,31) |
| X3 | 0,08 (0,18) | 0,05 (0,01-0,13) | -0,01 (0,19) | 0,02 (–0,03-0,04) |
| X4 | 0,47 (0,33) | 0,48 (0,26-0,71) | 0,22 (0,31) | 0,19 (0,07-0,39) |
| X5 | 1,67 (1,7) | 1,31 (0,77-2,1) | 1,12 (1,24) | 0,74 (0,27-1,6) |
DT: desviación típica; P: percentil.
X1: (Activo circulante – Pasivo líquido) / Total activo.
X2: Reservas / Total activo.
X3: EBIT / Total activo.
X4: Patrimonio neto / Deudas totales.
X5: Ingresos de explotación / Total activo.
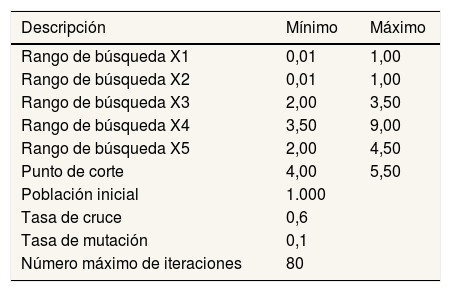
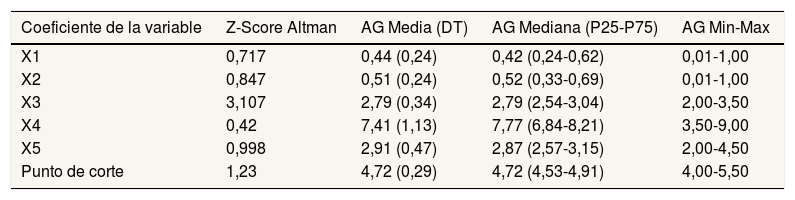
Como ya se ha mencionado, los AG se utilizaron para obtener unos coeficientes mejorados y su respectivo punto de corte para la Z’-Score de Altman7 (la tabla 3 muestra los parámetros utilizados para controlar el proceso de los AG22). Dichos coeficientes, que son calculados como la media de las distintas soluciones óptimas que proporcionan los AG, se muestran en la tabla 4 junto con su mediana y los valores mínimos y máximos. También se muestran los valores originales propuestos por Altman. De este modo, la fórmula 2 presenta el modelo de Altman con los coeficientes mejorados:
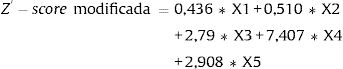
Parámetros utilizados en los AG
| Descripción | Mínimo | Máximo |
|---|---|---|
| Rango de búsqueda X1 | 0,01 | 1,00 |
| Rango de búsqueda X2 | 0,01 | 1,00 |
| Rango de búsqueda X3 | 2,00 | 3,50 |
| Rango de búsqueda X4 | 3,50 | 9,00 |
| Rango de búsqueda X5 | 2,00 | 4,50 |
| Punto de corte | 4,00 | 5,50 |
| Población inicial | 1.000 | |
| Tasa de cruce | 0,6 | |
| Tasa de mutación | 0,1 | |
| Número máximo de iteraciones | 80 |
X1: (Activo circulante – Pasivo líquido) / Total activo.
X2: Reservas / Total activo.
X3: EBIT / Total activo.
X4: Patrimonio neto / Deudas totales.
X5: Ingresos de explotación / Total activo.
Coeficientes Z-Score de Altman y estadística descriptiva de las soluciones obtenidas en el proceso AG
| Coeficiente de la variable | Z-Score Altman | AG Media (DT) | AG Mediana (P25-P75) | AG Min-Max |
|---|---|---|---|---|
| X1 | 0,717 | 0,44 (0,24) | 0,42 (0,24-0,62) | 0,01-1,00 |
| X2 | 0,847 | 0,51 (0,24) | 0,52 (0,33-0,69) | 0,01-1,00 |
| X3 | 3,107 | 2,79 (0,34) | 2,79 (2,54-3,04) | 2,00-3,50 |
| X4 | 0,42 | 7,41 (1,13) | 7,77 (6,84-8,21) | 3,50-9,00 |
| X5 | 0,998 | 2,91 (0,47) | 2,87 (2,57-3,15) | 2,00-4,50 |
| Punto de corte | 1,23 | 4,72 (0,29) | 4,72 (4,53-4,91) | 4,00-5,50 |
DT: desviación típica; P: percentil.
X1: (Activo circulante – Pasivo líquido) / Total activo.
X2: Reservas / Total activo.
X3: EBIT / Total activo.
X4: Patrimonio neto / Deudas totales.
X5: Ingresos de explotación / Total activo.
El número de soluciones encontradas a lo largo del proceso es 551.346.
Para poder interpretar el resultado de la fórmula debe tenerse en cuenta lo siguiente:
- •
Si el resultado es mayor que 4,715 (punto de corte obtenido a través de los AG), la previsión es que la empresa no tendrá riesgo.
- •
Si el resultado es menor o igual que 4,715, la previsión es que la empresa está en riesgo de entrar en concurso de acreedores.
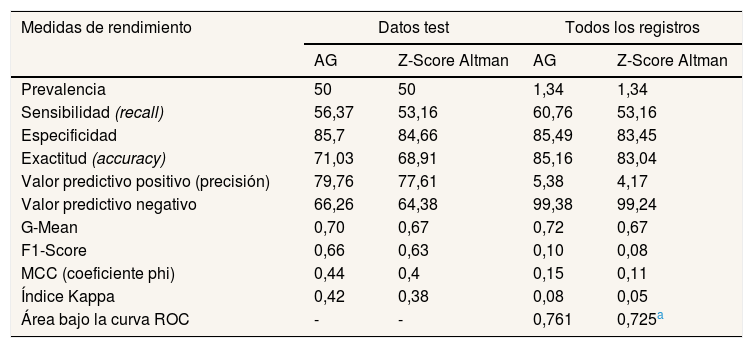
Las principales diferencias entre el modelo original y el propuesto en este trabajo se encuentran en los coeficientes de las variables X4 y X5 (véanse las fórmulas 1 y 2). Una vez calculados los coeficientes mejorados se procedió a comprobar si realmente proporcionan una mejor predicción. La tabla 5 muestra los resultados de las medidas de rendimiento obtenidos durante el proceso de ejecución del conjunto de datos utilizados para el test. Se puede apreciar cierta mejoría en el modelo propuesto respecto del modelo original de Altman.
Comparación de las medidas de rendimiento con todos los datos del test y todos los registros
| Medidas de rendimiento | Datos test | Todos los registros | ||
|---|---|---|---|---|
| AG | Z-Score Altman | AG | Z-Score Altman | |
| Prevalencia | 50 | 50 | 1,34 | 1,34 |
| Sensibilidad (recall) | 56,37 | 53,16 | 60,76 | 53,16 |
| Especificidad | 85,7 | 84,66 | 85,49 | 83,45 |
| Exactitud (accuracy) | 71,03 | 68,91 | 85,16 | 83,04 |
| Valor predictivo positivo (precisión) | 79,76 | 77,61 | 5,38 | 4,17 |
| Valor predictivo negativo | 66,26 | 64,38 | 99,38 | 99,24 |
| G-Mean | 0,70 | 0,67 | 0,72 | 0,67 |
| F1-Score | 0,66 | 0,63 | 0,10 | 0,08 |
| MCC (coeficiente phi) | 0,44 | 0,4 | 0,15 | 0,11 |
| Índice Kappa | 0,42 | 0,38 | 0,08 | 0,05 |
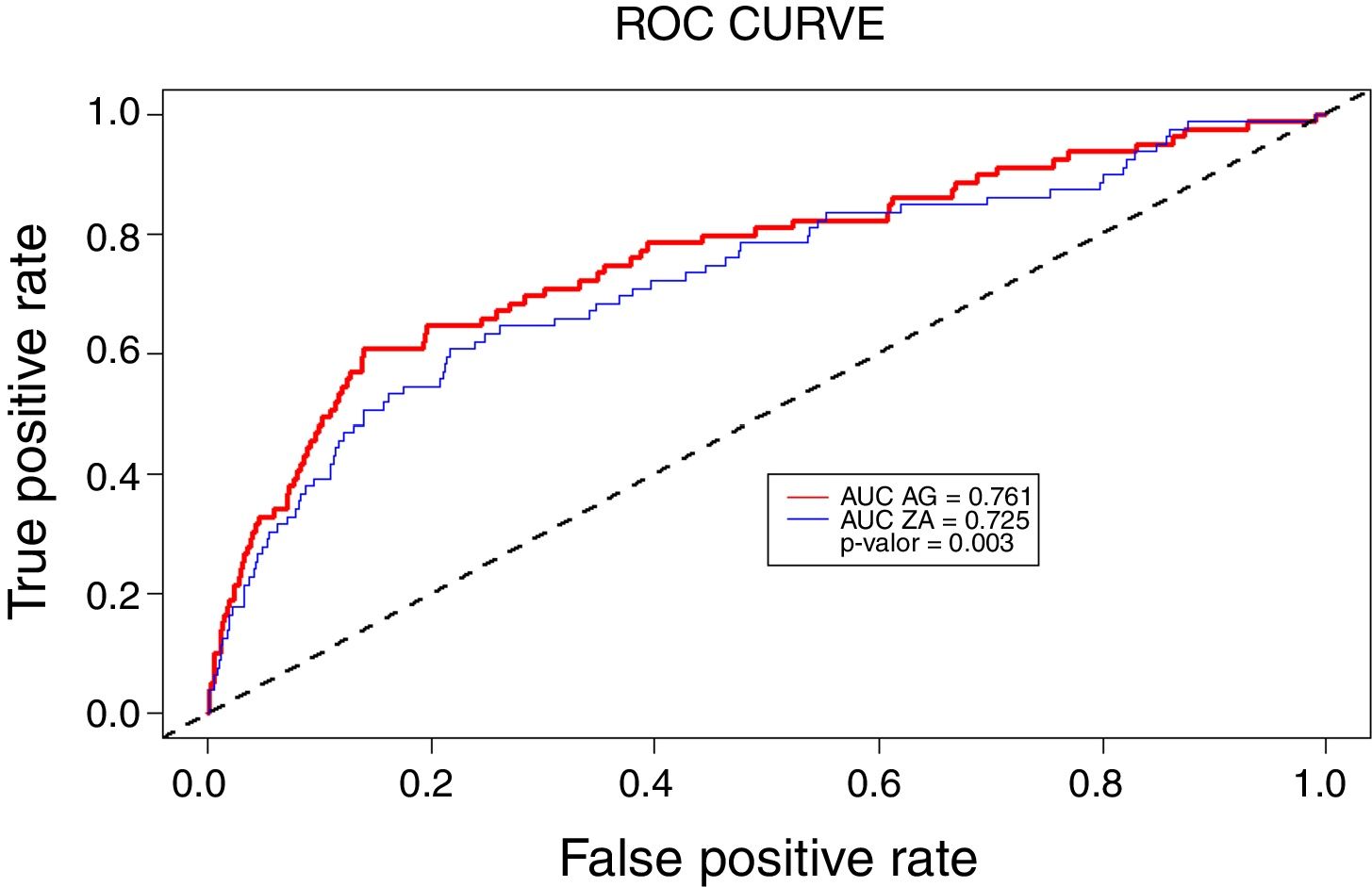
| Área bajo la curva ROC | - | - | 0,761 | 0,725a |
MCC: coeficiente de correlación de Matthews.
Por otra parte, también se presenta la comparación de ambos modelos aplicados a la totalidad de los registros. Se observa cómo la sensibilidad mejora 7,6 puntos, la especificidad 2,04 puntos y el área bajo la curva ROC 3,6 puntos (estos datos se han obtenido a través de la matriz de confusión mostrada en la tabla IV del Apéndice online). En la figura I del Apéndice online se muestran las curvas ROC, en las que se aprecia el mayor poder predictivo del nuevo modelo.
DiscusiónLa importancia del sector sanitario privado en España es una realidad de la que prácticamente nadie duda. Si a ello se une que el servicio que presta es crítico para la salud de las personas, resulta evidente que contar con empresas saneadas es una cuestión relevante. Así, poder conocer con antelación que una empresa tiene una alta probabilidad de tener problemas financieros es de gran interés para la propia empresa, ya que podría tomar medidas para paliar dicha situación. También lo sería para proveedores y clientes, pues tendrían una mayor información y, por tanto, más seguridad para plantear relaciones a largo plazo.
Por otro lado, cada sector económico posee unas características y peculiaridades financieras que las diferencian de otros. La rotación de activos, la rentabilidad, la liquidez, los ingresos, el endeudamiento, los tiempos de cobro a clientes o pago a proveedores, etc., son solo algunos de los parámetros que los diferencian32,33. Consecuentemente, tratar a todas las empresas de la misma forma para predecir si están saneadas o no puede inducir a errores en dicha predicción.
Por todo ello, en el presente trabajo se ha propuesto la mejora de uno de los modelos predictivos más utilizados, la Z’-Score de Altman. Esto se ha hecho estableciendo unos coeficientes para las ratios que propone el autor y un nuevo punto de corte, calculados ad hoc para el sector sanitario privado español. En el caso del sector sanitario, la diferenciación parece encontrarse en las variables patrimonio neto, deudas totales e ingresos de explotación. A la luz de los resultados, se observa que los nuevos coeficientes presentan una pequeña mejora respecto a las predicciones obtenidas con el modelo original de Altman7, reduciéndose los errores de tipo I y tipo II, es decir, se reducen las predicciones erróneas tanto de empresas en concurso de acreedores como de empresas sanas. No debe pasarse por alto que, en el mundo empresarial, ambos problemas son graves. Predecir que una empresa puede entrar en concurso de acreedores cuando realmente está sana puede estigmatizarla, complicándole el acceso a créditos o provocando que sus clientes y proveedores la abandonen por falta de credibilidad34. Por otra parte, si el error es el contrario, es decir, considerarla sana cuando realmente no lo está, pone en riesgo a sus clientes y proveedores.
Por otro lado, puede afirmarse que los resultados obtenidos (exactitud del 85,16%) van en la misma dirección que varios modelos predictivos comentados previamente: para Odom y Sharda15 del 81,81%, y para Shin y Lee10 del 80,8%. Así, se obtiene un resultado similar en la evolución de la formula Z’-Score de Altman propuesta por Almamy et al.31, que obtienen una exactitud del 82,9%. En relación con el área bajo la curva ROC, la mejoría observada en este artículo es similar a la observada por Altman et al.35 en su comparación entre modelos con información financiera y un segundo modelo en el que se añaden variables con información no financiera.
Finalmente, cabe señalar que las limitaciones de este estudio radican en que el uso de AG no garantiza que se encuentre la solución óptima del problema. Estas soluciones dependerán del rango de búsqueda, del tamaño de la población, y de las ratios de cruce y de mutación aplicadas. En cuanto a futuras líneas de investigación, podrían utilizarse otras técnicas de inframuestreo, como la validación cruzada de k-iteraciones. Por otro lado, sería interesante aplicar la metodología seguida en este trabajo a subsectores más específicos dentro del sector sanitario. Evidentemente, esto solo podrá hacerse cuando se tenga un número suficiente de empresas en concurso de acreedores.
Se han propuesto diversas fórmulas para predecir la bancarrota en distintos sectores industriales y países. La Z-Score de Altman es una de las más utilizadas en el mundo financiero. Dicha fórmula general para empresas privadas ha sido adaptada para empresas con determinadas características, pero nunca para el sector sanitario.
¿Qué añade el estudio realizado a la literatura?Se aporta una metodología que, para las empresas sanitarias privadas españolas, permite optimizar los coeficientes que multiplican a las ratios propuestos en la Z-Score de Altman, logrando así una fórmula que permite realizar predicciones más eficientes.
David Cantarero.
Declaración de transparenciaEl autor principal (garante responsable del manuscrito) afirma que este manuscrito es un reporte honesto, preciso y transparente del estudio que se remite a Gaceta Sanitaria, que no se han omitido aspectos importantes del estudio, y que las discrepancias del estudio según lo previsto (y, si son relevantes, registradas) se han explicado.
Contribuciones de autoríaA. Sánchez Medina es el responsable del artículo, contribuyó con la concepción y dirección del estudio, la recogida de datos, el análisis, el diseño del estudio, la interpretación de los datos y la elaboración final del manuscrito, y con importantes contribuciones intelectuales. José Mª González-Martín contribuyó con la concepción del estudio, la recogida de datos, el análisis, el diseño del estudio, la interpretación de los datos y la elaboración final del manuscrito, y con importantes contribuciones intelectuales. Jesús B. Alonso contribuyó con la concepción del estudio, la recogida de datos, el análisis, el diseño del estudio, la interpretación de los datos y la elaboración final del manuscrito, y con importantes contribuciones intelectuales. Todos los autores aprobaron la versión final del trabajo enviado.
FinanciaciónNinguna.
Conflictos de interesesNinguno.












