






Gran parte de la investigación biomédica es de tipo observacional. Los informes de los estudios observacionales a menudo poseen una calidad insuficiente, lo que dificulta la evaluación de sus fortalezas y debilidades para generalizar los resultados. Teniendo en cuenta la evidencia empírica y consideraciones teóricas, un grupo de expertos en metodología, investigadores y editores de revistas científicas, desarrollaron una lista de recomendaciones para aumentar la calidad de las publicaciones de los estudios observacionales: Strenghtening the Reporting of Observational Studies in Epidemiology (STROBE). La Declaración STROBE consiste en una lista de verificación de 22 puntos que guardan relación con las diferentes secciones de un artículo: título, resumen, introducción, metodología, resultados y discusión. De ellos, 18 puntos son comunes a los tres diseños de estudio: cohorte, casos y controles, y transversales; los otros cuatro son específicos para cada una de estas tres modalidades. La Declaración STROBE proporciona a los autores información sobre cómo mejorar la calidad de los artículos sobre estudios observacionales y facilita a los revisores, editores de revistas y lectores su apreciación crítica y su interpretación. Este documento explicativo tiene el propósito de impulsar el uso, la comprensión y la difusión de la Declaración STROBE. Se presentan el significado y el análisis razonado para cada punto de la lista de verificación, proporcionando uno o varios ejemplos publicados en la literatura y, en lo posible, referencias de estudios empíricos relevantes y literatura metodológica. También se incluyen ejemplos de diagramas de flujo. La Declaración STROBE, el presente documento y la página Web asociada (http://www.strobe-statement.org/) son recursos útiles para mejorar la divulgación de la investigación observacional.
Much medical research is observational. The reporting of observational studies is often of insufficient quality. Poor reporting hampers the assessment of the strengths and weaknesses of a study and the generalisability of its results. Taking into account empirical evidence and theoretical considerations, a group of methodologists, researchers, and editors developed the Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) recommendations to improve the quality of reporting of observational studies. The STROBE Statement consists of a checklist of 22 items, which relate to the title, abstract, introduction, methods, results and discussion sections of articles. Eighteen items are common to cohort studies, case-control studies and cross-sectional studies and four are specific to each of the three study designs. The STROBE Statement provides guidance to authors about how to improve the reporting of observational studies and facilitates critical appraisal and interpretation of studies by reviewers, journal editors and readers. This explanatory and elaboration document is intended to enhance the use, understanding, and dissemination of the STROBE Statement. The meaning and rationale for each checklist item are presented. For each item, one or several published examples and, where possible, references to relevant empirical studies and methodological literature are provided. Examples of useful flow diagrams are also included. The STROBE Statement, this document, and the associated Web site (http://www.strobe-statement.org/) should be helpful resources to improve reporting of observational research.
La práctica racional del cuidado de la salud requiere del conocimiento sobre la etiología, la patogénesis, el diagnóstico, el pronóstico y el tratamiento de las enfermedades. Los ensayos clínicos aleatorizados proporcionan una valiosa evidencia sobre los tratamientos y otras intervenciones. Sin embargo, gran parte del conocimiento clínico o de salud pública proviene de la investigación observacional1. Nueve de cada 10 artículos de investigación publicados en revistas de especialidades clínicas describen investigaciones observacionales2,3.
La declaración STROBECon frecuencia, la comunicación de estudios observacionales no es lo suficientemente clara y detallada para evaluar las fortalezas y las debilidades de la investigación4,5. Para mejorarla, desarrollamos una lista de verificación de los puntos que se deben atender: la Declaración STROBE, que recientemente se ha publicado en varias revistas científicas6. Estos puntos se relacionan con las secciones de título, resumen, introducción, métodos, resultados y discusión. Nuestro propósito es asegurar una presentación clara de lo que se planeó, realizó y encontró en un estudio observacional. Hacemos énfasis en que estas recomendaciones no son recetas para planificar o conducir estudios y tampoco dictan la metodología ni decretan una presentación uniforme.
La declaración STROBE proporciona recomendaciones generales para estudios observacionales descriptivos y aquellos que investigan asociaciones entre variables de exposición y resultados de salud. Comprende los tres tipos principales de estudios observacionales: de cohortes, de casos y controles, y transversales. Los autores utilizan terminología diversa para describir estos diseños. Por ejemplo, “estudio de seguimiento” y “estudio longitudinal” se utilizan como sinónimos para el estudio de cohortes, y “estudio de prevalencia” como sinónimo de “estudio transversal”. Elegimos la actual terminología porque es de uso común. Desafortunadamente, con frecuencia estos términos se utilizan de forma incorrecta7 o imprecisa8. En el Recuadro 1 describimos las características distintivas de los tres diseños de estudio.
Principales diseños de estudio tratados por STROBE.
Los diseños de cohortes, casos y controles, y transversales, constituyen diferentes enfoques para investigar la ocurrencia de eventos relacionados con la salud en una población y en un periodo de tiempo determinados. Estos estudios pueden abordar muchos tipos de eventos relacionados con la salud, incluyendo la enfermedad o su remisión, la discapacidad o las complicaciones, la muerte o la supervivencia, así como la presencia de factores de riesgo.
En los estudios de cohortes, los investigadores siguen a las personas durante un periodo de tiempo. Obtienen información acerca de ellas y de su exposición basal, dejan que pase el tiempo y posteriormente comprueban la presencia de eventos resultado. Los investigadores comúnmente hacen comparaciones entre los individuos expuestos y no expuestos, o bien entre grupos de individuos con diferentes categorías de exposición. También pueden medir varios eventos diferentes y examinar variables de exposición y eventos en diversos momentos durante el periodo de seguimiento. Las cohortes cerradas (por ejemplo, cohortes desde el nacimiento) reclutan un número definido de participantes al inicio del estudio y los siguen de ahí en adelante, a menudo a intervalos predeterminados, hasta una fecha final también fijada. En las cohortes abiertas, la población en estudio es dinámica: las personas entran y salen del estudio en diferentes momentos en el tiempo (por ejemplo, los habitantes de una comunidad). Las cohortes abiertas cambian debido a muertes, nacimientos y migración, pero la composición de la población respecto a variables como edad y sexo puede permanecer aproximadamente constante,en especialmente en un periodo de tiempo corto. En una cohorte cerrada se pueden estimar las incidencias acumuladas (riesgos) y las tasas de incidencia; cuando se comparan los grupos de expuestos y no expuestos, es posible estimar la razón de riesgos o la razón de tasas. Las cohortes abiertas estiman tasas de incidencia y razones de tasas.
En los estudios de casos y controles, los investigadores comparan exposiciones entre personas con una enfermedad particular (casos) y personas sin esa enfermedad (controles). Reúnen casos y controles que sean representativos de una cohorte subyacente o de una muestra de una población. Esa población puede estar definida geográficamente, o provenir de la zona de influencia del centro de atención de salud. La muestra de casos puede ser del 100% o una fracción grande de casos disponibles, mientras que la muestra de controles generalmente es sólo una pequeña fracción de personas que no tienen la enfermedad en estudio. Los controles representan la cohorte o población de personas de la cual surgieron los casos. Los investigadores calculan la odds ratio de las exposiciones para las supuestas causas de la enfermedad entre los casos y los controles (véase el Recuadro 7). Dependiendo de la estrategia de muestreo para casos y controles, y de la naturaleza de la población estudiada, la odds ratio obtenida en un estudio de casos y controles se interpreta como la razón de riesgos, razón de tasas u odds ratio para la prevalencia16,17. La mayoría de los estudios de casos y controles publicados muestrean cohortes abiertas, lo que les permite estimar directamente las razones de tasas.
En los estudios transversales, los investigadores estudian a todos los individuos de una muestra en el mismo momento en el tiempo, y con frecuencia investigan la prevalencia de exposiciones, factores de riesgo o enfermedades. Algunos estudios transversales son analíticos y están dirigidos a cuantificar posibles asociaciones causales entre exposiciones y enfermedades. Tales estudios pueden analizarse como un estudio de cohortes mediante la comparación de la prevalencia de enfermedad entre los grupos de exposición. También pueden analizarse como un estudio de casos y controles al comparar la razón de exposición entre los grupos con y sin enfermedad. Un problema que puede surgir en cualquier diseño epidemiológico, pero que es particularmente evidente en los estudios transversales, es establecer que la exposición precedió a la enfermedad aun cuando, algunas veces, el orden en el tiempo de la exposición y el evento pueda estar claro. Por ejemplo, en un estudio en que la variable de exposición es congénita o genética, podemos estar seguros de que la exposición precedió a la enfermedad, aunque estemos midiendo ambas al mismo tiempo.
Los estudios observacionales sirven a una amplia gama de propósitos: desde la información sobre un primer indicio de la posible causa de una enfermedad, hasta la verificación de la magnitud de asociaciones previamente comunicadas. Las ideas para los estudios pueden surgir de observaciones clínicas o del refinamiento del conocimiento biológico, así como de observaciones informales de datos que conducen a mayores exploraciones. Del mismo modo que un clínico ve miles de pacientes y alguno llama su atención, el investigador puede fijarse en algo especial en los datos observados. No es posible ni deseable corregir las interpretaciones mediante la revisión múltiple de los datos9, pero a menudo son necesarios nuevos estudios para confirmar o refutar las observaciones iniciales10.
Los datos existentes se pueden utilizar para investigar nuevas ideas sobre posibles factores causales, y pueden ser suficientes para rechazar o confirmar una hipótesis. En otros casos, posteriormente se diseñan estudios específicos para superar los problemas que pueden haberse encontrado en comunicaciones previas. Estos estudios recopilarán nuevos datos y se planificarán para ese propósito, en contraste con los análisis de datos existentes. Esto conduce a diversos puntos de vista, por ejemplo respecto a la formación de subgrupos o a la importancia de un tamaño de muestra predeterminado. STROBE intenta incluir estos diferentes usos de la investigación observacional, desde el descubrimiento hasta la refutación o la confirmación. Cuando sea necesario indicaremos en qué circunstancias específicas se aplican las recomendaciones.
Cómo utilizar este documentoEste documento está ligado a la versión breve de la Declaración STROBE, que presentó en varias revistas6 la lista de puntos a verificar y forma parte integral de la Declaración STROBE. Nuestra intención es explicar cómo informar adecuadamente de la investigación, no cómo ésta debe llevarse a cabo. Ofrecemos una explicación detallada para cada punto de la lista. Cada explicación va precedida por un ejemplo de lo que consideramos un informe adecuado. Esto no significa que el estudio de donde se ha tomado el ejemplo esté bien escrito en su totalidad, y tampoco que sus resultados sean fiables, ni que posteriormente sean confirmados por otros estudios; significa solamente que este punto en particular está bien escrito y comunicado. Además de explicaciones y ejemplos, incluimos los recuadros 1 a 8 con información adicional. Estos recuadros están dedicados a los lectores que deseen refrescar su memoria sobre algunos aspectos teóricos o quieran informarse rápidamente sobre detalles de cuestiones técnicas. Su completa comprensión puede requerir estudiar los libros de texto o los documentos metodológicos que se citan.
Las recomendaciones de STROBE no tratan específicamente temas como estudios de asociaciones genéticas, modelos de enfermedades infecciosas, informes o series de casos11,12. Sin embargo, muchos de los elementos de STROBE pueden aplicarse a estos diseños, por lo que los autores que comuniquen tales estudios pueden encontrar útiles estas recomendaciones. Para los autores de artículos sobre estudios observacionales que traten específicamente pruebas diagnósticas, marcadores tumorales y asociaciones genéticas15, las recomendaciones STARD13, REMARK14 y STREGA pueden ser particularmente útiles.
Los puntos de la lista de verificaciónA continuación comentamos y explicamos los 22 puntos de la lista de verificación STROBE (tabla 1), y ofrecemos ejemplos publicados para cada uno de ellos. Algunos de estos ejemplos se han reproducido eliminando referencias o abreviaturas. Dieciocho de los puntos se aplican a los tres diseños de estudio, mientras que los otros cuatro son específicos. Los puntos con asterisco (por ejemplo el número 8*) indican que la información se debe dar por separado para los casos y los controles en los estudios de casos y controles, y para los grupos expuestos y no expuestos en los estudios de cohortes y transversales. Aconsejamos a los autores tratar todos los puntos en alguna parte de su artículo, pero no indicamos una localización ni un orden exactos. Por ejemplo, hablamos de la comunicación de resultados en puntos separados, pero reconocemos que los autores pueden tratar varios puntos dentro de una sola sección del texto o en una tabla.
Declaración STROBE: lista de puntos esenciales que deben describirse en la publicación de estudios observacionales
| Título y resumen | Punto | Recomendación |
| 1 | (a) Indique, en el título o en el resumen, el diseño del estudio con un término habitual | |
| (b) Proporcione en el resumen una sinopsis informativa y equilibrada de lo que se ha hecho y lo que se ha encontrado | ||
| Introducción | ||
| Contexto/ fundamentos | 2 | Explique las razones y el fundamento científicos de la investigación que se comunica |
| Objetivos | 3 | Indique los objetivos específicos, incluyendo cualquier hipótesis preespecificada |
| Métodos | ||
| Diseño del estudio | 4 | Presente al principio del documento los elementos clave del diseño del estudio |
| Contexto | 5 | Describa el marco, los lugares y las fechas relevantes, incluyendo los periodos de reclutamiento, exposición, seguimiento y recogida de datos |
| Participantes | 6 | (a) Estudios de cohortes: proporcione los criterios de elegibilidad, así como las fuentes y el método de selección de los participantes. Especifique los métodos de seguimiento |
| Estudios de casos y controles: proporcione los criterios de elegibilidad, así como las fuentes y el proceso diagnóstico de los casos y el de selección de los controles. Indique las razones para la elección de casos y controles | ||
| Estudios transversales: proporcione los criterios de elegibilidad, y las fuentes y los métodos de selección de los participantes | ||
| (b) Estudios de cohortes: en los estudios pareados, proporcione los criterios para la formación de parejas y el número de participantes con y sin exposición | ||
| Estudios de casos y controles: en los estudios pareados, proporcione los criterios para la formación de las parejas y el número de controles por cada caso | ||
| Variables | 7 | Defina claramente todas las variables: de respuesta, exposiciones, predictoras, confusoras y modificadoras del efecto. Si procede, proporcione los criterios diagnósticos |
| Fuentes de datos/medidas | 8* | Para cada variable de interés, indique las fuentes de datos y los detalles de los métodos de valoración (medida). Si hubiera más de un grupo, especifique la comparabilidad de los procesos de medida |
| Sesgos | 9 | Especifique todas las medidas adoptadas para afrontar posibles fuentes de sesgo |
| Tamaño muestral | 10 | Explique cómo se determinó el tamaño muestral |
| Variables cuantitativas | 11 | Explique cómo se trataron las variables cuantitativas en el análisis. Si procede, explique qué grupos se definieron y por qué |
| Métodos estadísticos | 12 | (a) Especifique todos los métodos estadísticos, incluidos los empleados para controlar los factores de confusión |
| (b) Especifique todos los métodos utilizados para analizar subgrupos e interacciones | ||
| (c) Explique el tratamiento de los datos ausentes (missing data) | ||
| (d) Estudios de cohortes: si procede, explique cómo se afrontan las pérdidas en el seguimiento | ||
| Estudios de casos y controles: si procede, explique cómo se parearon casos y controles | ||
| Estudios transversales: si procede, especifique cómo se tiene en cuenta en el análisis la estrategia de muestreo | ||
| (e) Describa los análisis de sensibilidad | ||
| Resultados | ||
| Participantes | 13* | (a) Indique el número de participantes en cada fase del estudio; p. ej., número de participantes elegibles, analizados para ser incluidos, confirmados elegibles, incluidos en el estudio, los que tuvieron un seguimiento completo y los analizados |
| (b) Describa las razones de la pérdida de participantes en cada fase | ||
| (c) Considere el uso de un diagrama de flujo | ||
| Datos descriptivos | 14* | (a) Describa las características de los participantes en el estudio (p. ej., demográficas, clínicas, sociales) y la información sobre las exposiciones y los posibles factores de confusión |
| (b) Indique el número de participantes con datos ausentes en cada variable de interés | ||
| (c) Estudios de cohortes: resuma el periodo de seguimiento (p. ej., promedio y total) | ||
| Datos de las variables de resultado | 15* | Estudios de cohortes: indique el número de eventos resultado o bien proporcione medidas resumen a lo largo del tiempo |
| Estudios de casos y controles: indique el número de participantes en cada categoría de exposición o bien proporcione medidas resumen de exposición | ||
| Estudios transversales: indique el número de eventos resultado o bien proporcione medidas resumen | ||
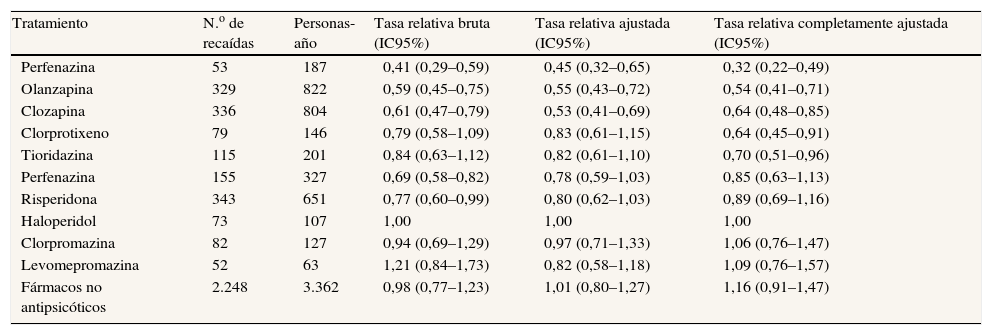
| Resultados principales | 16 | (a) Proporcione estimaciones no ajustadas y, si procede, ajustadas por factores de confusión, así como su precisión (p. ej., intervalos de confianza del 95%). Especifique los factores de confusión por los que se ajusta y las razones para incluirlos |
| (b) Si categoriza variables continuas, describa los límites de los intervalos | ||
| (c) Si fuera pertinente, valore acompañar las estimaciones del riesgo relativo con estimaciones del riesgo absoluto para un periodo de tiempo relevante | ||
| Otros análisis | 17 | Describa otros análisis efectuados (de subgrupos, interacciones o sensibilidad) |
| Discusión | ||
| Resultados clave | 18 | Resuma los resultados principales de los objetivos del estudio |
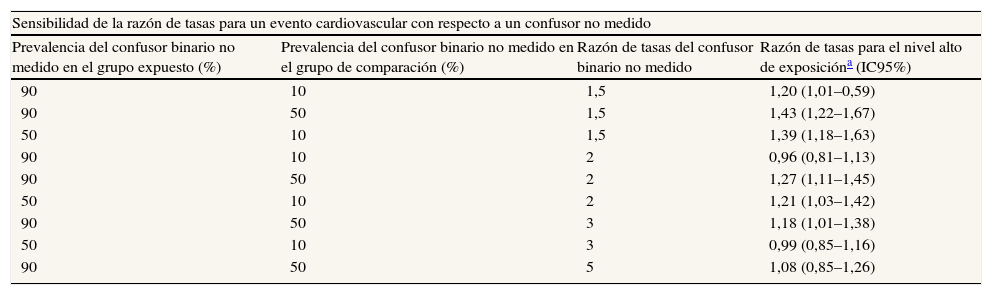
| Limitaciones | 19 | Discuta las limitaciones del estudio, teniendo en cuenta posibles fuentes de sesgo o de imprecisión. Razone tanto sobre la dirección como sobre la magnitud de cualquier posible sesgo |
| Interpretación | 20 | Proporcione una interpretación global prudente de los resultados considerando objetivos, limitaciones, multiplicidad de análisis, resultados de estudios similares y otras pruebas empíricas relevantes |
| Generabilidad | 21 | Discuta la posibilidad de generalizar los resultados (validez externa) |
| Otra información | ||
| Financiación | 22 | Especifique la financiación y el papel de los patrocinadores del estudio, y si procede, del estudio previo en que se basa su artículo |
Nota: Se ha publicado un artículo que explica y detalla la elaboración de cada punto de la lista, y se ofrece el contexto metodológico y ejemplos reales de comunicación transparente. La lista de puntos STROBE se debe utilizar preferiblemente junto con ese artículo (gratuito en las páginas web de las revistas PLoS Medicine (http://www.plosmedicine.org/), Annals of Internal Medicine (http://www.annals.org/) y Epidemiology (http://www.epidem.com/). En la página web de STROBE (http://www.strobe-statement.org) aparecen las diferentes versiones de la lista correspondientes a los estudios de cohortes, a los estudios de casos y controles, y a los estudios transversales.
Los puntos
Título y resumen
1 (a). Indique el diseño del estudio en el título o en el resumen con un término habitualEjemplo“Incidencia de leucemia entre trabajadores de la industria manufacturera de zapatos y botas: un estudio de casos y controles”18.
ExplicaciónLos lectores deben poder identificar fácilmente, desde el título o el resumen, el diseño que se utilizó. Un término explícito utilizado habitualmente para el diseño del estudio, ayuda también a asegurar la correcta indexación del artículo en las bases de datos electrónicas19,20.
1 (b). Proporcione en el resumen una sinopsis informativa y equilibrada de lo que se ha hecho y lo que se ha encontradoEjemplo“Antecedentes: la supervivencia esperada en los pacientes infectados por el VIH es de fundamental interés para la Salud Pública.
Objetivo: estimar el tiempo de supervivencia y las tasas de mortalidad específicas para la edad de una población infectada por VIH en comparación con la mortalidad en la población general.
Diseño: estudio de cohortes de base poblacional.
Contexto: todas las personas infectadas con VIH que recibieron atención en Dinamarca de 1995 a 2005.
Pacientes: cada miembro del estudio de la cohorte nacional danesa de VIH se emparejó hasta con 99 personas de la población general según sexo, fecha de nacimiento y lugar de residencia.
Mediciones: los autores calcularon las tablas de vida de Kaplan-Meier con la edad como escala de tiempo para estimar la supervivencia desde los 25 años. Se observó a los pacientes infectados con VIH y a las personas correspondientes de la población general a partir de la fecha del diagnóstico del VIH hasta su muerte, migración o el 1 de mayo de 2005.
Resultados: se incluyeron en el estudio 3.990 pacientes infectados por el VIH y 379.872 personas de la población general, que produjeron 22.744 personas-año (mediana 5,8) y 2.689.287 personas-año (mediana 8,4) de observación. Se perdió el 3% de los participantes durante el seguimiento. A partir de los 25 años de edad, la mediana del tiempo de supervivencia para los pacientes infectados fue 19,9 años (IC95%: 18,5–21,3), y 51,1 años (IC95%: 50,9–51,5) para la población general. Para los pacientes infectados, la supervivencia aumentó a 32,5 años (IC95%: 29,4–34,7) durante el periodo 2000–2005. En el subgrupo que excluyó a personas con coinfección por el virus de la hepatitis C (16%), la mediana de la supervivencia fue 38,9 años (IC95%: 35,4–40,1) durante este mismo periodo. La tasa de mortalidad relativa para los pacientes con infección por VIH comparada con la de la población general disminuyó con el aumento de la edad, mientras que el exceso de la tasa de mortalidad se incrementó con la edad.
Limitaciones: se asumió que las tasas de mortalidad observadas serían aplicables más allá del tiempo máximo de observación de 10 años.
Conclusiones: la mediana estimada del tiempo de supervivencia es de más de 35 años para una persona joven diagnosticada de infección por VIH en la última etapa del tratamiento antirretroviral de gran actividad. Sin embargo, se necesita un esfuerzo continuo para reducir más las tasas de mortalidad de estas personas comparadas con la población general”21.
ExplicaciónEl resumen proporciona la información clave que permite al lector entender el estudio y decidir si lee o no el artículo. Los componentes típicos incluyen la pregunta de investigación, una breve descripción de los métodos y los resultados, y una conclusión22. Los resúmenes deben sintetizar detalles clave del estudio y presentar solamente la información que se proporciona en el artículo. Aconsejamos la presentación de los resultados principales en cifras, incluyendo el número de participantes, las estimaciones de asociaciones y las medidas apropiadas de la variabilidad y de la incertidumbre (por ejemplo odds ratio con intervalo de confianza). Creemos insuficiente indicar solamente si una exposición se asocia o no de manera significativa con el resultado.
Una serie de encabezados referentes a los antecedentes, el diseño, el desarrollo y el análisis del estudio pueden ayudar a los lectores a obtener rápidamente la información esencial23. Muchas revistas requieren estos resúmenes estructurados, que tienden a ser de mayor calidad y más informativos que los no estructurados24,25.
IntroducciónLa sección de introducción debe describir por qué se llevó a cabo el estudio y qué preguntas de investigación e hipótesis trata. Debe permitir que otros comprendan el contexto del estudio y que juzguen su posible contribución al conocimiento actual.
2. Contexto/fundamentos: explique las razones y el fundamento científicos de la investigación que se comunicaEjemplo“La preocupación por el aumento de la prevalencia de la obesidad en niños y adolescentes se ha centrado en las bien documentadas asociaciones entre la obesidad infantil y el aumento del riesgo cardiovascular y la mortalidad en la edad adulta. La obesidad infantil tiene considerables consecuencias sociales y psicológicas, tanto en la niñez como en la adolescencia; no obstante, poco se sabe sobre sus consecuencias sociales, socioeconómicas y psicológicas en la edad adulta. Una revisión sistemática reciente no encontró estudios longitudinales sobre las consecuencias de la obesidad infantil, a excepción de los efectos físicos sobre la salud, y solamente dos estudios longitudinales sobre los efectos socioeconómicos de la obesidad en la adolescencia. Gortmaker et al. encontraron que mujeres norteamericanas que habían sido obesas al final de la adolescencia, en 1981, tenían menos probabilidades de estar casadas y menores ingresos siete años después que las mujeres que no habían tenido sobrepeso, mientras que los hombres que tenían sobrepeso era menos probable que estuvieran casados. En Gran Bretaña, Sargent et al. encontraron que las mujeres, pero no los hombres, que habían sido obesas a los 16 años en 1974, ganaban un 7,4% menos que sus pares no obesas a la edad de 23 años. (…) Utilizamos datos longitudinales de la cohorte de nacimientos británicos de 1970 para examinar las consecuencias socioeconómicas, educativas, sociales y psicológicas, en la edad adulta, de la obesidad infantil”26.
ExplicaciónLos antecedentes científicos del estudio proporcionan un contexto importante a los lectores. Establecen la etapa en que se ubica el estudio y describen su propósito. Ofrecen una descripción de lo que se sabe acerca del tema y qué vacíos del conocimiento actual se tratan en el estudio. La información de los antecedentes debe centrarse en estudios recientes y en todas las revisiones sistemáticas de estudios pertinentes.
3. Objetivos: indique los objetivos específicos, incluyendo cualquier hipótesis preespecificadaEjemploNuestros objetivos principales fueron: 1) determinar la prevalencia de la violencia doméstica entre mujeres que solicitaron consulta médica en cuatro centros comunitarios de atención primaria que atienden a pacientes de diversos estratos socioeconómicos, y 2) identificar diferencias demográficas y clínicas entre las pacientes que sufrieron abusos recientemente y las que no”27.
ExplicaciónLos objetivos son los propósitos detallados del estudio. Los objetivos bien elaborados especifican la población, las exposiciones y los efectos, así como los parámetros que serán estimados. Pueden formularse como hipótesis específicas o como preguntas que el estudio pretende abordar. En algunas situaciones los objetivos pueden ser menos específicos, por ejemplo en las etapas tempranas de una investigación. Independientemente de ello, el informe debe reflejar claramente las intenciones de los investigadores. Por ejemplo, si durante el análisis de datos se distinguieron subgrupos importantes o se realizaron análisis no previstos con referencia al propósito original del estudio, es necesario incluir la descripción correspondiente (véase también los puntos 4, 17 y 20).
MétodosLa sección de métodos debe describir lo que se planeó y lo que se hizo con suficiente detalle para permitir a otros entender los aspectos esenciales del estudio, para juzgar si los métodos fueron adecuados para proporcionar respuestas fiables y válidas, así como para evaluar si cualquier desviación del plan original fue razonable.
4. Diseño del estudio: presente al principio del documento los elementos clave del diseño del estudioEjemplo“Usamos un diseño de casos alternantes o cruzados (case-crossover), que es una variante del diseño de casos y controles útil cuando una exposición breve (uso del teléfono mientras se conduce) causa un incremento pasajero en el riesgo de un desenlace de poca frecuencia (un accidente). Comparamos el uso del teléfono móvil por los conductores en el momento estimado de un accidente con los mismos conductores durante otro momento conveniente. Como los conductores son sus propios controles, este diseño tiene en cuenta algunas características del conductor que podrían afectar la probabilidad de chocar, pero que no cambian en un periodo corto. Como es importante que los riesgos sean similares durante los periodos de control y los trayectos en que ocurre el accidente, comparamos el uso del teléfono durante el intervalo de riesgo (tiempo inmediatamente anterior al accidente) con su uso durante los intervalos de control (periodos equivalentes durante los cuales los participantes estaban conduciendo pero no chocaron) en la semana previa”28.
ExplicaciónAconsejamos presentar al comienzo los elementos clave del diseño del estudio, en la sección de métodos (o al final de la introducción), de manera que los lectores comprendan los fundamentos del estudio. Por ejemplo, se debe indicar que el estudio fue de cohortes, que siguió a los participantes durante un periodo de tiempo concreto, y describir al grupo de personas que integran la cohorte y su estatus de exposición. Igualmente, si la investigación usó un diseño de casos y controles se deben describir los casos y los controles, así como la fuente de la población. Si se trata de una encuesta hay que mencionar la población y el momento en que se tomó la muestra. Cuando se trate de una variante de los tres principales tipos de estudio, se requieren aclaraciones adicionales. Por ejemplo, respecto a un estudio de casos alternantes, que es una variante del diseño de casos y controles, en el ejemplo previo se ofreció una breve descripción de sus principios28.
Recomendamos que los autores se abstengan de llamar simplemente a un estudio “prospectivo” o “retrospectivo”, porque estos términos están mal definidos29. Un enfoque es entender “cohorte” y “prospectivo” como sinónimos, y reservar la palabra “retrospectivo” para estudios de casos y controles30. Un segundo enfoque distingue los estudios de cohortes en prospectivos y retrospectivos, basándose en el momento en que surgió la idea del estudio y la temporalidad para recoger los datos31. Un tercer enfoque distingue estudios de casos y controles prospectivos y retrospectivos, dependiendo de si los datos acerca de la exposición de interés existían cuando se seleccionaron los casos32. Algunos recomiendan no utilizar estos términos33 o adoptar las opciones “concurrente” e “histórica” para describir estudios de cohortes34. En STROBE no usamos las palabras “prospectivo” y “retrospectivo”, ni opciones como “concurrente” e “histórica”. Recomendamos que, siempre que los autores utilicen estos términos, definan su significado. Más importante aún, recomendamos que los autores describan exactamente cómo y cuándo tuvo lugar la recogida de los datos.
La primera parte de la sección de métodos puede ser también el lugar apropiado para mencionar si el reporte es uno de varios otros derivados de un mismo estudio. Si un artículo está en línea con los propósitos originales del estudio, normalmente se indica refiriéndose a una publicación anterior y repitiendo de forma breve las características relevantes del estudio. Sin embargo, los propósitos del estudio también pueden evolucionar con el tiempo. Con frecuencia los investigadores usan datos con propósitos para los cuales no fueron planeados en principio, incluyendo, por ejemplo, estadísticas vitales que se elaboran principalmente con fines administrativos, preguntas de cuestionarios que originalmente sólo se incluyeron para hacer los datos más completos, o muestras de sangre tomadas con otros propósitos. Por ejemplo, el Physicians’ Health Study, un ensayo controlado aleatorizado de ácido acetilsalicílico y carotenos, se utilizó posteriormente para demostrar que una mutación puntual en el gen del factor V se asociaba con un mayor riesgo de trombosis venosa, pero no con infarto de miocardio ni con enfermedad vascular cerebral35. El uso secundario de datos existentes es una parte creativa de las investigaciones observacionales, y no necesariamente hace a los resultados menos creíbles o menos importantes. Sin embargo, repetir brevemente los intereses originales del estudio puede ayudar a los lectores a comprender el contexto de la investigación y las posibles limitaciones de los datos.
5. Contexto: describa el marco, los lugares y las fechas relevantes, incluyendo los periodos de reclutamiento, exposición, seguimiento y recogida de datosEjemplo“El Estudio de Cohortes Los Pasitos reclutó mujeres embarazadas de las clínicas de mujeres, recién nacidos y niños en Socorro y San Elizario, en el condado de El Paso, Texas, y de las clínicas materno-infantiles del Instituto Mexicano de Seguridad Social en Ciudad Juárez, México, de abril de 1998 a octubre de 2000. Al inicio, previamente al nacimiento de los niños incluidos en la cohorte, se entrevistó a las madres respecto al ambiente familiar. Para el estudio nos propusimos realizar exámenes de seguimiento con intervalos de 6 meses, comenzando a los 6 meses de edad”36.
ExplicaciónLos lectores necesitan información sobre el entorno y la ubicación para evaluar el contexto y la generalización de los resultados del estudio. Las exposiciones, los factores ambientales y los tratamientos pueden cambiar con el tiempo, así como también los métodos de estudio pueden evolucionar a lo largo del tiempo. Saber cuándo tuvo lugar un estudio y durante qué periodos fueron reclutados y seguidos los participantes, sitúa al estudio en un contexto histórico y es importante para la interpretación de los resultados.
La información acerca del marco incluye sitios o fuentes de reclutamiento (por ejemplo una lista electoral, una consulta externa, un registro de cáncer o centros de tercer nivel). La información sobre el lugar se puede referir a países, ciudades, hospitales o servicios clínicos donde tuvo lugar la investigación. Aconsejamos indicar las fechas en vez de sólo la extensión de los periodos de tiempo. Pueden existir diferentes fechas para determinar la exposición, la ocurrencia de la enfermedad, el reclutamiento, el comienzo y el fin del seguimiento, y la recogida de los datos. Cabe señalar que cerca del 80% de 132 artículos de revistas de oncología que usaron análisis de supervivencia incluían las fechas iniciales y finales para la acumulación de los pacientes, pero sólo el 24% indicaba la fecha en que terminó el seguimiento37.
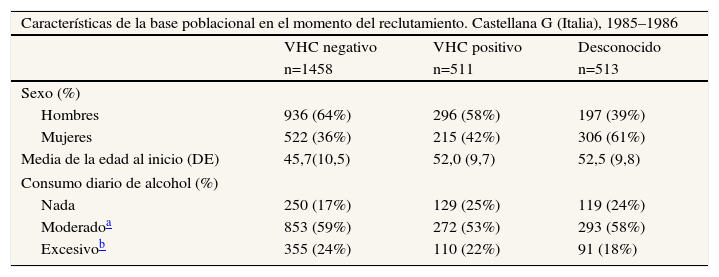
6. Participantes6 (a). Estudios de cohortes: proporcione los criterios de elegibilidad, así como las fuentes y el método de selección de los participantes. especifique los métodos de seguimientoEjemplo
“Las participantes en el Iowa Women's Health Study fueron una muestra aleatoria de todas las mujeres de 55 a 69 años de edad obtenida de la lista de licencias de conducir del Estado de Iowa en 1985, que representaban aproximadamente el 94% de las mujeres de ese Estado en ese grupo de edad. (…) Los cuestionarios de seguimiento se enviaron por correo en octubre de 1987 y en agosto de 1989, para evaluar el estado vital y cambios de domicilio. (…) Se identificaron los cánceres incidentes, excepto el cáncer de piel tipo no melanoma, mediante el Registro Estatal de Salud de Iowa. (…) La cohorte del estudio fue emparejada con el Registro, con combinaciones de nombre, apellido y nombre de soltera, código postal, fecha de nacimiento y número de la seguridad social”38.
6 (a). Estudios de casos y controles: proporcione los criterios de elegibilidad, así como las fuentes y el proceso diagnóstico de los casos y el de selección de los controles. indique las razones para la elección de casos y controlesEjemplo“Se identificaron los casos de melanoma cutáneo diagnosticados en 1999 y 2000 mediante del Registro de Cáncer de Iowa. (…) Los controles, también identificados por el mismo registro, fueron pacientes con cáncer colorrectal diagnosticados en el mismo periodo. Se seleccionaron controles con cáncer colorrectal debido a que son frecuentes y tienen una supervivencia relativamente larga, y porque la exposición a arsénico no se ha vinculado concluyentemente con la incidencia de cáncer colorrectal”39.
6 (a). Estudios transversales: proporcione los criterios de elegibilidad, y las fuentes y los métodos de selección de los participantesEjemplo“Identificamos retrospectivamente pacientes con un diagnóstico principal de infarto de miocardio (código 410) según la Modificación Clínica de la Novena Revisión de la Clasificación Internacional de Enfermedades. De los códigos designados se descartaron diagnósticos excluyendo aquellos códigos cuyo quinto dígito fuera 2, que indica un episodio de atención subsecuente. (…) Se seleccionó una muestra aleatoria de la cohorte completa de Medicare con infarto de miocardio de febrero de 1994 a julio de 1995. (…) Para ser elegibles, los pacientes tenían que presentarse en el hospital transcurridos al menos 30 minutos con dolor de pecho, pero menos de 12horas, y haber tenido una elevación del segmento ST de al menos 1mm en dos derivaciones contiguas en el electrocardiograma inicial”40.
ExplicaciónLa descripción detallada de los participantes del estudio ayuda a los lectores a entender la aplicabilidad de los resultados. Los investigadores normalmente restringen la población de estudio mediante la definición de características clínicas, demográficas y otras, entre los participantes elegibles. Los criterios de elegibilidad típicos se relacionan con la edad, el sexo, el diagnóstico y las condiciones de comorbilidad. A pesar de su importancia, a menudo los criterios de elegibilidad no se describen adecuadamente. En un estudio sobre investigaciones observacionales sobre accidentes vasculares y cerebrales, 17 de 49 reportes (35%) no especificaron los criterios de elegibilidad5.
Los criterios de elegibilidad se pueden presentar como criterios de inclusión y exclusión, aunque esta distinción no siempre es necesaria o útil. No obstante, aconsejamos a los autores indicar todos los criterios de elegibilidad y describir el grupo del cual se seleccionó la población de estudio (por ejemplo la población general de una región o país), así como el método de reclutamiento (por ejemplo referencia o autoselección mediante anuncios).
Conocer los detalles sobre los procedimientos de seguimiento, incluyendo si éstos minimizaron la no respuesta y las pérdidas, así como si los procedimientos fueron similares para todos los participantes, permite juzgar la validez de los resultados. Por ejemplo, en un estudio que usó anticuerpos IgM para detectar infecciones agudas, los lectores necesitaban saber el intervalo entre los análisis de sangre para estos anticuerpos, de modo que pudieran estimar si se omitieron algunas infecciones debido a intervalos demasiado prolongados entre las pruebas41. En otros estudios en que los procedimientos de seguimiento difieran entre los grupos expuestos y no expuestos, los lectores podrían reconocer un sesgo sustancial debido a una evaluación desigual de los eventos a observar, a diferencias en la no respuesta o a pérdidas en el seguimiento42. Por lo tanto, aconsejamos que los investigadores describan los métodos usados para el seguimiento, si fueron los mismos para todos los participantes y cuán completa fue la medición de las variables (ver también punto 14).
En los estudios de casos y controles, la elección de los casos y de los controles es crucial para interpretar los resultados, y el método de selección tiene implicaciones importantes para la validez del estudio. En general, los controles deben reflejar la población de donde surgen los casos. Se emplean varios métodos para muestrear a los controles, todos con ventajas y desventajas: para casos que surgen de una población general se emplean controles de muestras de listas de población, marcación de números telefónicos aleatorios, amigos o vecinos. Los controles de amigos o vecinos pueden presentar pareamiento intrínseco en la exposición17. Los controles con otras enfermedades pueden tener ventajas sobre los controles de base poblacional, en particular para casos hospitalarios, porque reflejan mejor la captación poblacional de un hospital, tienen una mayor comparabilidad recordatoria y son fáciles de reclutar. Sin embargo, pueden presentar problemas si la exposición de interés afecta al riesgo de desarrollar o ser hospitalizado por la condición de control43,44. Para corregir este problema, con frecuencia se emplea una combinación de controles con las enfermedades probablemente menos asociadas a la exposición45.
6 (b). Estudios de cohortes: en los estudios pareados, proporcione los criterios para la formación de parejas y el número de participantes con y sin exposiciónEjemplo“Para cada paciente que inicialmente recibió estatinas usamos un enparejamiento basado en la propensión para identificar un control que no recibiera estatinas, según el siguiente protocolo. Primero se calculó la puntuación de propensión para cada paciente en toda la cohorte basándose en una larga lista de factores potencialmente relacionados con el uso de estatinas o con el riesgo de sepsis. Segundo, cada usuario de estatinas fue emparejado con un grupo más pequeño de no usuarios de estatinas por sexo, edad (±1 año) y la fecha índice (±3 meses). Tercero, seleccionamos el control con la puntuación de propensión más cercana (dentro del 0,2 de desviación estándar) para cada usuario de estatinas con una razón 1:1, y descartamos los controles restantes”46.
6 (b). Estudios de casos y controles: en los estudios emparejados, proporcione los criterios para la formación de las parejas y el número de controles por cada casoEjemplo“Nos propusimos seleccionar cinco controles por cada caso entre individuos de la población de estudio que no tuvieran diagnóstico de autismo ni otro trastorno generalizado del desarrollo (TGD) registrado en su expediente de atención primaria, y que estuvieran vivos y registrados como pacientes activos en la fecha del diagnóstico del TGD del caso. Los controles fueron pareados individualmente con los casos por año de nacimiento (hasta un año mayor o menor), sexo y centro de atención primaria. Para cada uno de los 300 casos se pudo identificar cinco controles que cumplieran todos los criterios de emparejamiento. Para los 994 restantes se excluyeron uno o más controles47.
ExplicaciónEl pareamiento es mucho más común en estudios de casos y controles, pero en ocasiones los investigadores lo usan en los estudios de cohortes para hacer grupos comparables en el inicio del seguimiento. El pareamiento en los estudios de cohortes proporciona grupos directamente comparables por posibles confusores, y presenta menos complejidad que en los estudios de casos y controles. Por ejemplo, no es necesario tener en cuenta el pareamiento para la estimación del riesgo relativo. Ya que en los estudios de cohortes el pareamiento puede aumentar la precisión estadística, los investigadores pueden permitir el pareamiento en sus análisis y además obtener intervalos de confianza más estrechos.
Los estudios de casos y controles pareados se realizan para incrementar la eficiencia del estudio y asegurar la similitud en la distribución de las variables entre casos y controles, en particular la distribución de las variables potencialmente confusoras48,49. Puesto que el pareamiento se puede hacer de varias formas, con uno o más controles por caso, se deben describir la justificación para la selección de variables de emparejamiento y los detalles de los métodos utilizados. Las formas de emparejamiento comúnmente usadas son por frecuencia (también llamado “pareamiento o emparejamiento de grupo”) e individual. En el pareamiento por frecuencia, los investigadores eligen controles de manera que la distribución de las variables de pareamiento sea idéntica o similar que la de los casos. El pareamiento individual implica parear uno o varios controles a cada caso. Aunque intuitivamente es atractivo y algunas veces útil, el pareamiento en los estudios de casos y controles tiene ciertas desventajas, no siempre es apropiado y debe tenerse en cuenta en el análisis (véase el Recuadro 2).
Pareamiento en estudios de casos y controles.
En cualquier estudio de casos y controles es necesario tomar decisiones razonables respecto a si usar pareamiento, y de ser así qué variables parear, el método preciso para hacerlo y el apropiado análisis estadístico. El hecho de no parear por ninguna variable puede significar que la distribución de algunos posibles confusores (p.ej., edad, sexo) sea radicalmente diferente entre casos y controles. Si bien en el análisis puede ajustarse por estas variables, es probable que haya una pérdida importante de la eficiencia estadística.
El uso del pareamiento en los estudios de casos y controles, así como su interpretación, están llenos de dificultades, especialmente si se parea por varios factores de riesgo, algunos de los cuales pueden estar asociados a la exposición de interés50,51. Por ejemplo, en un estudio de casos y controles sobre infarto de miocardio y anticonceptivos orales, anidado en una gran base de datos farmacoepidemiológica, con información sobre miles de mujeres disponibles como posibles controles, los investigadores pueden estar tentados a elegir controles pareados con similares factores de riesgo por cada caso de infarto de miocardio. Un objetivo es ajustar por factores que pueden influir en la prescripción de anticonceptivos orales, y de esta manera controlar la confusión por indicación. Sin embargo, el resultado será un grupo control que deja de ser representativo del uso de anticonceptivos orales en la población base: los controles serán más viejos que la población base debido a que los pacientes con infarto de miocardio tienden a ser más viejos. Esto tiene varias implicaciones. Un análisis crudo de los datos puede producir odds ratios normalmente sesgadas hacia la unidad si el factor de pareamiento está asociado con la exposición. La solución es realizar un análisis pareado o estratificado (véase el punto 12b). Asimismo, debido a que el grupo de controles pareados dejó de ser representativo de la población, la distribución de la exposición entre los controles no puede usarse para estimar la fracción atribuible poblacional (véase el Recuadro 7)52. Además, ya no se puede estudiar el efecto del factor de pareamiento, y la búsqueda de controles bien pareados puede ser engorrosa, lo que hace preferible un diseño no pareado debido a que los controles no pareados serían más sencillos de obtener y el grupo control puede ser más grande. El sobrepareamiento es otro problema que puede reducir la eficiencia de los estudios de casos y controles pareados, y en algunas situaciones puede introducir sesgos. La información se pierde y el poder del estudio se reduce si la variable de pareamiento está estrechamente asociada con la exposición. Por lo tanto, muchos individuos dentro de los mismos grupos pareados tenderán a tener idénticas o similares exposiciones, y por lo tanto no contribuyen con información relevante. El pareamiento irremediablemente introducirá sesgos si la variable de pareamiento no es un confusor sino que se encuentra en la ruta causal entre la exposición y la enfermedad. Por ejemplo, la fertilización in vitro está asociada con un riesgo elevado de muerte perinatal, debido a un aumento de los nacimientos múltiples y del bajo peso al nacer53. Parear por pluralidad o peso al nacer sesgará los resultados hacia la nulidad, y esto no se puede remediar en el análisis.
El pareamiento es intuitivamente atractivo, pero la complejidad que implica ha llevado a los metodólogos a advertir contra la sistematización del pareamiento en los estudios de casos y controles. Recomiendan hacer una consideración cuidadosa y juiciosa de cada posible factor de pareamiento, reconociendo que pueden ser determinados y usados como una variable de ajuste en lugar de parear por ellos. En consecuencia, ha habido una reducción en el número de factores de pareamiento utilizados y un uso creciente del pareamiento por frecuencia, lo que evita algunos de los problemas comentados anteriormente, así como más estudios de casos y controles no pareados en absoluto54. El pareamiento continúa siendo lo más deseable, e incluso necesario, cuando la distribución de los confusores (p.ej., la edad) puede diferir radicalmente entre los grupos de comparación no pareados48,49.
Incluso procedimientos de paremiento simples en apariencia pueden ser mal comunicados. Por ejemplo, los autores pueden establecer que los controles se parearon a los casos “dentro de un periodo de 5 años” o “usando intervalos de edad de 5 años”. ¿Esto significa que, si un caso tenía 54 años de edad, el respectivo control necesitaba estar en el intervalo de los 5 años, de 50 a 54, o con una edad de 49 a 59, que está dentro de los 5 años a partir de la edad de 54? Si se elige un intervalo de edad amplio (por ejemplo 10 años) hay riesgo de una confusión residual por edad (véase también el Recuadro 4), ya que, por ejemplo, los controles pueden ser en promedio más jóvenes que los casos.
7. Variables: defina claramente todas las variables, de respuesta, exposiciones, predictoras, confusoras y modificadoras del efecto. si procede, proporcione los criterios diagnósticosEjemplo“Sólo se incluyeron en el análisis malformaciones congénitas importantes. Se excluyeron las anomalías secundarias según la lista de exclusión de las Anomalías Congénitas del Registro Europeo (EUROCAT). Si un niño tenía más de una malformación congénita importante en un órgano, estas malformaciones fueron tratadas como un evento resultado en el análisis por sistema de órganos. (…) En el análisis estadístico, los factores considerados como posibles confusores fueron la edad materna en el momento del parto y el número de partos previos. Los factores considerados como posibles modificadores del efecto fueron la edad materna en el momento del reembolso del medicamento antiepiléptico y la edad materna en el parto”55.
ExplicaciónLos autores deben definir todas las variables consideradas e incluidas en el análisis, de respuesta, exposiciones, predictoras y posibles confusoras y modificadoras del efecto. Las enfermedades resultado requieren una descripción detallada y adecuada de los criterios diagnósticos. Esto es de aplicación a los criterios para casos en un estudio de casos y controles, a los eventos de enfermedad durante el seguimiento en un estudio de cohortes, y a la enfermedad prevalente en un estudio transversal. Son particularmente importantes las definiciones claras y los pasos tomados para adherirse a ellas para cualquier enfermedad de interés principal en el estudio.
Para algunos estudios, “determinante” y “predictor” pueden ser términos apropiados para variables de exposición, y las de resultado pueden llamarse desenlaces. En modelos multivariados, algunas veces los autores usan “variable dependiente” para un resultado y “variable independiente” o “variable explicatoria” para la exposición y las variables confusoras. Esto último no es necesario, ya que no distingue la exposición de los confusores.
Si se han medido e incluido muchas variables en el análisis exploratorio en una fase temprana de la investigación, considere proporcionar una lista con detalles sobre cada variable en un apéndice, tabla adicional o publicación separada. El International Journal of Epidemiology ha creado recientemente una nueva sección con “perfiles de cohortes”, que incluye información detallada sobre lo que se midió en diferentes momentos en el tiempo en estudios particulares56,57. Finalmente, recomendamos a los autores que declaren todas las “variables candidatas” consideradas para el análisis estadístico, en lugar de indicar selectivamente sólo las incluidas en los modelos finales (ver también el punto 16a)58,59.
8. Fuentes de datos/medidas: para cada variable de interés, indique las fuentes de datos y los detalles de los métodos de valoración (medida). si hubiera más de un grupo, especifique la comparabilidad de los procesos de medidaEjemplo 1“Se calculó principalmente el consumo de cafeína total usando las fuentes de composición de alimentos del Departamento de Agricultura de Estados Unidos. En estos cálculos se asumió que el contenido de cafeína era de 137mg por taza de café, 47mg por taza de té, 46mg por lata o botella de bebida de cola, y 7mg por ración de chocolate. Este método de medida del consumo (cafeína) mostró ser válido tanto en el estudio de la cohorte NHS I como en un estudio de una cohorte similar de profesionales de la salud varones. (…) Se halló que el diagnóstico autorreportado de hipertensión era fiable en la cohorte NHS I”60.
Ejemplo 2“Las muestras pertenecientes a los casos y los controles pareados se analizaron siempre juntas en la misma serie, y el personal del laboratorio no podía distinguir entre casos y controles”61.
ExplicaciónLa forma en que se miden la exposición, los confusores y los resultados afecta la fiabilidad y la validez de un estudio. El error de medida y la mala clasificación de la exposición o el resultado pueden hacer más difícil detectar una relación causa-efecto, o pueden producir relaciones falsas. El error en la medida de posibles confusores puede incrementar el riesgo de confusión residual62,63. Por lo tanto, es útil que los autores comuniquen los hallazgos de cualquier estudio de validez o fiabilidad de las evaluaciones o medidas, incluyendo detalles del estándar de referencia que se utilizó. En lugar de simplemente citar los estudios de validación (como en el primer ejemplo), aconsejamos que los autores proporcionen la validez y la fiabilidad estimadas que puedan utilizarse para un ajuste del error de medida o un análisis de sensibilidad (ver puntos 12e y 17).
Además, es importante saber si los grupos que se están comparando son diferentes respecto a la forma en que se recogieron los datos. Esto puede ser importante para análisis de laboratorio (como en el segundo ejemplo) y otras situaciones. Por ejemplo, si un entrevistador primero entrevista a todos los casos y después a los controles, o viceversa, es posible un sesgo debido a una curva de aprendizaje; soluciones como aleatorizar el orden de las entrevistas pueden evitar estos problemas. También pueden aparecer sesgos de información si a los grupos de comparación no se les aplican las mismas pruebas diagnósticas, o si un grupo recibe más pruebas del mismo tipo que el otro (ver también punto 9).
9. Sesgos: especifique todas las medidas adoptadas para afrontar posibles fuentes de sesgoEjemplo 1“En la mayoría de los estudios de casos y controles de suicidio el grupo control comprende individuos vivos, pero decidimos tener un grupo control de personas que murieron por otras causas. (…) Con un grupo control de individuos muertos, las fuentes de información utilizadas para evaluar los factores de riesgo son informantes que han experimentado recientemente la muerte de un familiar o de un conocido cercano, y por consiguiente son más comparables con las fuentes de información del grupo de suicidas que si se usaran controles vivos”64.
Ejemplo 2“El sesgo de descubrimiento podría influir en la asociación entre diabetes mellitus de tipo 2 (DMT2) y glaucoma primario de ángulo abierto (GPAA) si las mujeres con DMT2 estuvieran bajo una vigilancia oftálmica más estricta que las mujeres sin esta condición. Comparamos el número promedio de exploraciones oculares referido por las mujeres con y sin diabetes. También recalculamos el riesgo relativo de GPAA con un control adicional para covariables asociadas a una vigilancia ocular más cuidadosa (autorreporte de cataratas, degeneración macular, número de exploraciones oculares y número de exploraciones físicas)”65.
ExplicaciónLos estudios con sesgos producen resultados que difieren sistemáticamente de la verdad (véase también el Recuadro 3). Es importante para el lector saber qué medidas se tomaron durante el desarrollo del estudio para reducir los posibles sesgos. Idealmente, cuando planean el estudio los investigadores consideran con sumo cuidado las posibles fuentes de sesgo. En la fase del informe, recomendamos que evalúen siempre la probabilidad de sesgos relevantes. Específicamente debe considerarse la dirección y la magnitud del sesgo, y si es posible estimarlo. Por ejemplo, en los estudios de casos y controles la información puede sesgarse, pero puede reducirse seleccionando un grupo control apropiado, como en el primer ejemplo64. En el segundo ejemplo65, las diferencias en la vigilancia médica de las participantes era un problema. Por consiguiente, los autores proporcionan más detalles sobre los datos adicionales que recogieron para solucionar este problema. Se debe describir si los investigadores han establecido programas de control de calidad para la recogida de los datos, para contrarrestar un posible “cambio” en las medidas de las variables en estudios longitudinales o para mantener una mínima variabilidad cuando se utilizan observadores múltiples.
Sesgos.
Un sesgo es una desviación sistemática del valor verdadero del resultado de un estudio. Típicamente se introduce durante el diseño o el desarrollo de un estudio, y después ya no puede ser solucionado. Sesgo y confusor no son sinónimos. Un sesgo es el resultado de un defecto en la obtención de la información o la selección de los sujetos, de manera que se encuentra una asociación errónea. La confusión produce relaciones objetivamente ciertas, pero que no pueden ser interpretadas como causales debido a que un factor subyacente, no considerado, está asociado tanto con la exposición como con el resultado (véase el Recuadro 5). Asimismo, es necesario distinguir sesgo de error aleatorio, que es una desviación de un valor verdadero ocasionada por fluctuaciones estadísticas (en cualquier dirección) en la medida de los datos. Se han descrito muchas posibles fuentes de sesgo usando una variedad de términos68,69. Nosotros encontramos útiles dos categorías simples: sesgo de información y sesgo de selección.
El sesgo de información ocurre cuando diferencias sistemáticas en la completitud o la exactitud de los datos conducen a una mala clasificación diferencial de los individuos con respecto a las exposiciones o a los eventos resultado. Por ejemplo, si las mujeres diabéticas son sometidas a exámenes oculares más regulares y minuciosos, el hallazgo de glaucoma será más frecuente que en las mujeres sin diabetes (véase el punto 9)65. Los pacientes que toman un medicamento que causa molestias estomacales inespecíficas pueden someterse a una gastroscopia con más frecuencia y tener más ulceras detectadas que aquellos que no reciben el medicamento, aun cuando éste no ocasione más úlceras. Este tipo de sesgo de información también se conoce como “sesgo de detección” o “sesgo de vigilancia médica”. Una forma de evaluar su influencia es medir la intensidad de la vigilancia médica en los diferentes grupos de estudio, y ajustar por ésta en el análisis estadístico. En los estudios de casos y controles, el sesgo de información ocurre si los casos recuerdan las exposiciones pasadas con más precisión que los controles, o si tienen mejor disposición para relatarlas (también llamado “sesgo de recordatorio”). El “sesgo del entrevistador” puede ocurrir si los entrevistadores conocen la hipótesis de estudio y, de manera consciente o inconsciente, recogen información selectiva70. Por tanto, resulta valioso “cegar” a los participantes del estudio y a los investigadores.
El sesgo de selección puede introducirse en los estudios de casos y controles si la probabilidad de incluir casos o controles está asociada con la exposición. Por ejemplo, un médico que recluta pacientes para un estudio sobre trombosis venosa profunda es posible que diagnostique esta enfermedad en una mujer que tiene molestias en las piernas y toma anticonceptivos orales. Sin embargo, probablemente no la diagnostique en una mujer con molestias similares pero que no toma tales medicamentos. Este sesgo puede contrarrestarse usando casos y controles que sean remitidos de la misma forma al servicio donde se realice el diagnóstico71. Del mismo modo, el uso de registros de enfermedades puede introducir sesgo de selección: si se conoce una posible relación entre una exposición y una enfermedad, los casos pueden resultar más propensos a ser registrados si han estado expuestos al agente causal en estudio72. El “sesgo de respuesta” es otro tipo de sesgo de selección que ocurre si las diferencias en las características entre los que responden y los que no aceptan participar en un estudio afectan la estimación de las prevalencias, las incidencias y, en algunas circunstancias, las asociaciones. En general, el sesgo de selección afecta la validez interna de un estudio. Esto es diferente de los problemas que pueden presentarse con la selección de los participantes para un estudio en general, lo cual afecta la validez externa más que la interna (véase también el punto 21).
Desafortunadamente, a menudo los autores no refieren los sesgos importantes al comunicar sus resultados. De 43 estudios de casos y controles y de cohortes publicados entre 1990 y 1994 que investigaban el riesgo de segundos cánceres en pacientes con historia de cáncer, el sesgo de vigilancia médica se mencionaba sólo en cinco artículos66. Una encuesta de artículos sobre investigación en salud mental publicados en 1998 en tres revistas psiquiátricas encontró que sólo el 13% de 392 artículos mencionaban el sesgo de respuesta67. Un trabajo sobre estudios de cohortes sobre accidentes vasculares cerebrales encontró que 14 de 49 (28%) artículos publicados entre 1999 y 2003 indicaron un posible sesgo de selección en el reclutamiento de los participantes del estudio, y 35 (71%) mencionaban la posibilidad de que algún tipo de sesgo pudiera afectar sus resultados5.
10. Tamaño muestral: explique cómo se determinó el tamaño muestralEjemplo 1“El número de casos en el área durante el periodo de estudio determinó el tamaño de la muestra”73.
Ejemplo 2“Una encuesta sobre depresión posparto en la región había identificado una prevalencia del 19,8%. Asumiendo que la depresión en madres de niños con peso normal es del 20% y una odds ratio de 3 para depresión en madres de niños con desnutrición, necesitábamos 72 conjuntos de caso y control (un caso por un control) con un poder del 80% y una significación del 5%”74.
ExplicaciónUn estudio debe ser lo bastante grande como para obtener una estimación concreta con un intervalo de confianza suficientemente estrecho que conteste de manera significativa la pregunta de investigación. Se necesitan muestras grandes para distinguir una asociación pequeña. Los estudios pequeños a menudo proporcionan valiosa información; sin embargo, los intervalos de confianza amplios contribuyen poco al conocimiento actual, comparados con los estudios que proporcionan estimadores con intervalos de confianza más pequeños. También se publican con más frecuencia estudios pequeños que muestran asociaciones “estadísticamente significativas” o “interesantes” que estudios pequeños que no tienen resultados “significativos”. Aunque tales estudios pueden proporcionar una señal temprana acerca de una posible asociación, debe informarse a los lectores de sus posibles debilidades.
La importancia de determinar el tamaño de la muestra en los estudios observacionales depende del contexto. Si el análisis se realiza con datos que ya estaban disponibles para otros propósitos, la pregunta principal es si el análisis de los datos producirá resultados con la suficiente precisión estadística para contribuir sustancialmente a la literatura, y las consideraciones del tamaño de la muestra serán relativamente secundarias. El cálculo formal, a priori, del tamaño de la muestra puede ser útil cuando se planifica un nuevo estudio75,76. Tales cálculos se asocian con una mayor incertidumbre que la que implica la sola cifra que generalmente se produce. Por ejemplo, las estimaciones de la tasa del evento de interés u otras suposiciones centrales para los cálculos normalmente son imprecisas, si no meras conjeturas77. La precisión obtenida en el análisis final no puede determinarse de antemano, ya que se reducirá por la inclusión de las variables de confusión en los análisis multivariados78, por el grado de precisión con que se puedan medir las variables importantes79 o por la exclusión de algunos individuos.
Pocos estudios epidemiológicos explican las decisiones sobre el tamaño de la muestra4,5. Instamos a los investigadores para que describan el cálculo formal pertinente del tamaño de la muestra. En otras situaciones se deben indicar las consideraciones que determinaron el tamaño del estudio (por ejemplo, una muestra disponible fija, como en el primer ejemplo de arriba). Se debe mencionar si el estudio se concluyó antes, cuando se alcanzó la significación estadística. No importune a los lectores con justificaciones post hoc del tamaño del estudio o con cálculos de poder retrospectivos77. Desde el punto de vista del lector, los intervalos de confianza indican la precisión estadística que finalmente se obtuvo. Hay que tener en cuenta que los intervalos de confianza sólo reflejan la incertidumbre estadística, no toda la incertidumbre que puede estar presente en un estudio (veáse el punto 20).
11. Variables cuantitativas: explique cómo se trataron las variables cuantitativas en el análisis. si procede, explique qué grupos se definieron y por quEjemplo“Se considera que los pacientes con una puntuación menor de 8 en la Escala de Coma de Glasgow (GSC) presentan un daño grave. Una puntuación GCS de 9 o más indica una lesión cerebral menos grave. Investigamos la asociación de estos dos valores GCS con la ocurrencia de muerte dentro de los 12 meses siguientes a la lesión”80.
ExplicaciónLos investigadores toman decisiones respecto a cómo recoger y analizar los datos cuantitativos sobre las exposiciones, los modificadores del efecto y los confusores. Por ejemplo, pueden agrupar una exposición continua para crear una nueva variable categórica (véase el Recuadro 4). Las decisiones respecto al agrupamiento pueden tener consecuencias importantes para los análisis posteriores81,82. Recomendamos que los autores expliquen por qué y cómo se agruparon los datos cuantitativos, incluyendo el número de categorías, los puntos de corte y la media o la mediana de la categoría. Siempre que los datos se presenten en forma de tabla debe proporcionarse el número de casos, de controles, de personas en riesgo, de personas-tiempo, el riesgo, etc., para cada categoría. Las tablas no deben consistir solamente en estimaciones de la medida del efecto o resultados del ajuste del modelo.
Agrupación.
Los datos continuos pueden agruparse por diferentes razones86. Cuando se recogen datos es mejor buscar una variable ordinal más que intentar obtener una medida continua artificialmente precisa para una exposición que se basa en el recuerdo de varios años atrás. Las categorías también pueden ser útiles con propósitos de presentación, por ejemplo para presentar todas las variables en un estilo similar o para mostrar una relación dosis-respuesta.
También puede ser útil agrupar para simplificar el análisis, por ejemplo para evitar una suposición de linealidad. Sin embargo, al agrupar se pierde información y se puede reducir el poder estadístico87, en especial cuando se usa la dicotomización82,85,88. Si se agrupa un confusor continuo puede aparecer confusión residual, mediante la cual parte del efecto confusor de la variable permanece sin ajustar (véase el Recuadro 5)62,89. Aumentar el número de categorías puede disminuir la pérdida de poder y la confusión residual, y es especialmente apropiado en estudios grandes. Los estudios pequeños pueden usar pocos grupos debido a la limitación en los números.
Para fines prácticos, los investigadores pueden elegir puntos de corte como criterios de agrupación basándose en valores de uso común que son relevantes para el diagnóstico o el pronóstico. También pueden hacerlo por medio de criterios estadísticos. Pueden elegir igual número de individuos en cada grupo usando percentiles90. Por otro lado, se puede ganar más claridad en la asociación con el evento resultante eligiendo grupos extremos y manteniendo el grupo o grupos intermedios más grandes que los grupos de los extremos91. En los estudios de casos y controles es preferible derivar una distribución del grupo control debido a su intento por representar a la población base. Debe informarse a los lectores si los puntos de corte fueron seleccionados post hoc tras varias alternativas. En particular, si los puntos de corte fueron elegidos para minimizar un valor de p, la verdadera fuerza de una asociación puede estar exagerada81.
Cuando se analizan las variables agrupadas es importante reconocer su naturaleza continua subyacente. Por ejemplo, puede investigarse una posible tendencia en el riesgo a través de grupos ordenados. Un abordaje común es modelar el rango de los grupos como una variable continua. Tal linealidad en las puntuaciones de los grupos aproximará una asociación lineal real si los grupos están igualmente espaciados (por ejemplo, grupos con amplitud de 10 años de edad), pero no de otra forma. Il’yasova et al92 recomiendan publicar las estimaciones tanto categórica como continua del efecto, con sus errores estándar, a fin de facilitar el metaanálisis, así como proporcionar información intrínsecamente valiosa sobre dosis-respuesta. Un análisis puede informar sobre el otro y ninguno está libre de asunciones. Con frecuencia los autores ignoran el orden y consideran las estimaciones (y los valores de p) por separado para cada categoría, comparándolas con la de referencia. Esto puede ser útil para fines descriptivos, pero puede no serlo para detectar una tendencia real en el riesgo a través de los grupos. Si se observa una tendencia, un intervalo de confianza para una pendiente podría indicar la fuerza de la observación.
Los investigadores podrían modelar una exposición como continua con el fin de conservar toda la información. Al tomar esta decisión, se necesita considerar la naturaleza de la relación de la exposición con el resultado. Así como puede ser incorrecto asumir automáticamente una relación lineal, también deben investigarse posibles desviaciones de la linealidad. Los autores podrían mencionar los modelos alternativos que exploraron durante el análisis (por ejemplo, usando una transformación logarítmica, términos cuadráticos o funciones articuladoras). Existen varios métodos para ajustar una relación no lineal entre la exposición y el resultado82–84. También puede ser informativo presentar ambos análisis, el continuo y el agrupado, para una exposición cuantitativa de interés primario.
En un estudio reciente, dos tercios de las publicaciones epidemiológicas incluyeron variables de exposición cuantitativas4. En 42 de 50 artículos (84%), la exposición se agrupó en categorías ordenadas, pero sin justificar esta decisión. Quince artículos usaron asociaciones lineales para modelar la exposición continua, pero sólo dos verificaron la linealidad. En otro estudio sobre literatura de psicología85, la dicotomización sólo se justificaba en 22 de 110 artículos (20%).
12. Métodos estadísticos12 (a). especifique todos los métodos estadísticos, incluidos los empleados para controlar los factores de confusiónEjemplo
“Se calculó el riesgo relativo ajustado usando la técnica de Mantel-Haenzel para evaluar la presencia de confusión por edad o sexo en los grupos de comparación. Se estimó el intervalo de confianza (IC) del 95% del riesgo relativo ajustado, usando la varianza de acuerdo con Greenland y Robins, y Robins et al”93.
ExplicaciónEn general no hay un único análisis estadístico correcto, sino que más bien existen varias posibilidades que pueden atender a la misma cuestión haciendo diferentes suposiciones. Independientemente de esto, en el protocolo de investigación los investigadores deben determinar por anticipado al menos los análisis para los objetivos primarios del estudio. Con frecuencia se requieren análisis adicionales motivados por los datos, ya sea en lugar o además de los que originalmente se previeron. Al comunicar un estudio, los autores deben mencionar si los análisis particulares se debieron a la inspección de los datos. Aunque la distinción entre análisis preestablecido y exploratorio a veces puede ser ambigua, los autores deben aclarar las razones para los análisis particulares.
Si los grupos de comparación no son similares respecto a algunas características, el ajuste se debe hacer para las posibles variables confusoras mediante estratificación o regresión multivariada (véase el Recuadro 5)94. Con frecuencia el diseño del estudio determina la selección del tipo de análisis de regresión. Por ejemplo, la regresión de riesgo proporcional de Cox normalmente se usa en estudios de cohortes95, mientras que la regresión logística es a menudo el método de elección en los estudios de casos y controles96,97. Los analistas deben describir totalmente los procedimientos específicos para la selección de las variables, y no sólo presentar los resultados del modelo final98,99. Si se comparan modelos para determinar una lista de posibles confusores que se incluirán en un modelo final, también debe describirse este proceso. Es útil informar a los lectores de si una o dos covariables son causa de gran parte de la confusión aparente en un análisis de datos. También se deben describir otros análisis estadísticos, como los procedimientos de imputación, transformación de datos y cálculos de riesgos atribuibles. Se deben indicar las referencias de procedimientos novedosos o poco comunes, así como el software estadístico utilizado. Recomendamos que los métodos estadísticos se describan “con suficiente detalle para permitir al lector con conocimientos y acceso a los datos originales verificar los resultados comunicados”100.
Confusión.
Confusión significa literalmente “confusión de efectos”. Un estudio puede parecer estar mostrando una asociación o una no asociación entre una exposición y el riesgo de una enfermedad, y en realidad la aparente asociación o su falta se debe a otro factor que determina la ocurrencia de la enfermedad, pero que también está asociado con la exposición. Ese otro factor se conoce como “factor de confusión” o “confusor”. Por tanto, la confusión da lugar a una evaluación errónea de la posible asociación “causal” de una exposición. Por ejemplo, si a las mujeres que se acercan a la edad madura y desarrollan hipertensión se les prescribe con menor frecuencia anticonceptivos orales, una comparación simple de la frecuencia de enfermedad cardiovascular entre aquellas que usan anticonceptivos y las que no, puede dar la impresión equivocada de que los anticonceptivos protegen contra la enfermedad cardiaca.
Los investigadores deben pensar de antemano en los posibles factores de confusión. Esto ayudará a elegir el diseño del estudio y permitirá una recogida de datos adecuada, ya que al identificar los confusores será más sencillo guiar la búsqueda de información detallada. Pueden usarse la restricción o el pareamiento. En el ejemplo anterior, el estudio podría restringirse a mujeres que no tengan el confusor, la hipertensión. También se podría parear por la presión arterial, aunque no necesariamente es deseable (véase el Recuadro 2). En la fase de análisis, los investigadores pueden usar un análisis estratificado o un análisis multivariado para reducir el efecto de los confusores. La estratificación consiste en dividir los datos en estratos según el confusor (por ejemplo, estratificar por presión arterial), evaluar la estimación de la asociación dentro de cada estrato y calcular la estimación combinada de la asociación así como un promedio ponderado de todos los estratos. El análisis multivariado logra el mismo resultado, pero permite considerar otras variables simultáneamente. Es más flexible, pero puede implicar suposiciones adicionales acerca de la forma matemática de la relación entre la exposición y la enfermedad.
En los estudios observacionales es de suma importancia tener en cuenta los confusores; sin embargo, los lectores no deben asumir que el análisis ajustado por confusores establece la “parte causal” de una asociación. Los resultados todavía pueden estar distorsionados por confusión residual (la confusión que permanece después de intentos no exitosos de controlar por confusores102), por error de muestreo aleatorio, por sesgo de selección y por sesgo de información (véase el Recuadro 3).
En un estudio empírico, sólo 93 de 169 artículos (55%) que indicaban ajuste por confusión establecían claramente cómo se introdujeron las variables continuas y categóricas en el modelo estadístico101. Otro estudio encontró que en la mayoría de los 67 artículos en que los análisis estadísticos se ajustaban por confusores no estaba claro cómo se habían escogido éstos4.
12 (b). Especifique todos los métodos utilizados para analizar subgrupos e interaccionesEjemplo“Se exploraron las diferencias por sexo en la susceptibilidad a tres factores de riesgo relacionados con el estilo de vida, mediante la comprobación de la interacción biológica según Rothman: se redefinió una nueva variable compuesta por cuatro categorías para la variable sexo y una exposición de interés dicotómica (a−b−, a−b+, a+b− y a+b+), donde a− y b− indican ausencia de la exposición. Se calculó el RR para cada categoría después de ajustar por la edad. Se definió efecto de interacción por la aditividad de los efectos absolutos, y se calculó el exceso de RR causado por la interacción (RERI):
donde RR(a+b+) es el RR de aquellos expuestos a ambos factores y RR(a−b−) es la categoría de referencia (RR=1,0). Se calcularon los intervalos de confianza del 95% como proponen Hosmer y Lemeshow. Un RERI de 0 significa que no hay interacción”103.Explicación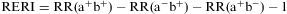
Como se comenta con detalle en el punto 17, el uso y el valor del análisis restringido de subgrupos de la población de estudio es objeto de debate4,104. No obstante, es frecuente que se hagan análisis de subgrupos4. Los lectores necesitan saber qué análisis de subgrupos se planificaron de antemano y cuáles surgieron mientras se analizaban los datos. También es importante explicar qué métodos se usaron para examinar si los efectos o asociaciones eran diferentes entre los grupos (veáse el punto 17).
La interacción se refiere a la situación en la cual un factor modifica el efecto de otro (de ahí la expresión “modificación del efecto”). La acción conjunta de dos factores se puede caracterizar de dos maneras: en una escala aditiva en términos de diferencias de riesgo, o en una escala multiplicativa en términos de riesgo relativo (véase el Recuadro 8). Muchos autores y lectores pueden tener preferencias sobre la manera en que deben analizarse las interacciones, e incluso pueden estar interesados en saber hasta qué punto el efecto conjunto de las exposiciones difiere de los efectos separados. Hay acuerdo general en que la escala aditiva, que usa los riesgos absolutos, es más apropiada para la toma de decisiones en salud pública y en la práctica clínica105. Cualquier punto de vista que se adopte debe presentarse claramente al lector, como se hace en el ejemplo anterior103. Lo más informativo puede ser una presentación que muestre los efectos de ambas exposiciones por separado y su efecto conjunto, cada una respecto a la no exposición. En el punto 17 se presenta el ejemplo de la interacción y en el Recuadro 8 se explican los cálculos sobre las diferentes escalas.
12 (c). Explique el tratamiento de los datos ausentes (missing data)Ejemplo“Nuestros procedimientos de análisis de datos ausentes se basaron en suposiciones de datos ausentes al azar. Usamos el método de imputación múltiple multivariada por ecuaciones encadenadas en STATA. Analizamos independientemente 10 copias de los datos, cada una con valores ausentes adecuadamente imputados en los análisis de regresión logística. Promediamos las estimaciones de las variables para dar una sola media estimada y los errores estándar ajustados según las reglas de Rubin”106.
ExplicaciónLos datos ausentes son comunes en la investigación observacional. Las encuestas enviadas por correo a los participantes no siempre están contestadas por completo, los participantes pueden no asistir a todas las visitas subsecuentes, y las fuentes habituales de datos, así como las bases de datos clínicos, a menudo están incompletas. A pesar de su ubicuidad e importancia, pocos artículos informan con detalle sobre el problema de los datos ausentes5,107. Los investigadores pueden usar cualquiera de varios enfoques para manejar los datos ausentes. En el Recuadro 6 describimos algunas ventajas y limitaciones de diversos planteamientos. Aconsejamos que los autores informen del número de valores ausentes para cada variable de interés (exposición, resultado, confusores) y para cada paso en el análisis. Si es posible, los autores deben dar las razones de los valores ausentes, e indicar cuántos individuos se excluyeron debido a datos ausentes al describir el flujo de participantes a lo largo del estudio (véase también el punto 13). Para los análisis que tengan en cuenta datos ausentes, los autores deben describir la naturaleza del análisis (por ejemplo, imputación múltiple) y las suposiciones que se hicieron (por ejemplo, pérdida al azar; véase el Recuadro 6).
Datos ausentes: problemas y posibles soluciones.
Un planteamiento común para tratar los datos ausentes es restringir el análisis a los individuos que tengan los datos completos de todas las variables requeridas para un análisis en particular. Si bien en muchas circunstancias los análisis con “casos completos” no están sesgados, también pueden estarlo y siempre son ineficientes108. El sesgo surge si los individuos con datos ausentes no son representativos de toda la muestra. La ineficiencia puede ocurrir debido a una reducción en el tamaño de muestra que será analizado.
Emplear la última observación en un diseño de medidas repetidas puede distorsionar las tendencias en el tiempo si las personas que intuyen el evento resultante abandonan selectivamente el estudio109. Insertar un indicador de dato ausente para un confusor puede aumentar la confusión residual107. La imputación, en la cual cada valor ausente es remplazado por un valor asumido o estimado, puede conducir a una atenuación o una exageración de la asociación de interés, y sin el uso de métodos sofisticados, como los que se describen más adelante, pueden producirse errores estándar muy pequeños.
Rubin108,110 desarrolló una tipología de problemas con datos ausentes basándose en un modelo para la probabilidad de que se pierda una observación. Los datos se describen como ausentes completamente al azar si la probabilidad de que una observación particular esté ausente no depende del valor de ninguna otra variable observable. Los datos son ausentes al azar si, considerando los datos observados, la probabilidad de que la observación esté ausente es independiente de los valores verdaderos del dato ausente. Por ejemplo, supongamos que los niños pequeños son más propensos a medidas ausentes de espirometría, pero que la probabilidad de ausencia no se relaciona con la función pulmonar real no observada, después de ajustar por la edad. Así, la medida de la función pulmonar sería del tipo ausentes al azar en los modelos que incluyen la edad. Los datos son ausentes no aleatoriamente si la probabilidad de ausencia depende del valor ausente aun después de tener en cuenta los datos disponibles. Cuando los datos son del tipo ausentes no aleatoriamente, para obtener inferencias válidas se requieren suposiciones explícitas sobre los mecanismos por los cuales se perdieron los datos.
Los métodos para tratar con datos ausentes al azar pueden ser de tres clases108,111: aproximaciones basadas en verosimilitud112, estimación ponderada113 e imputación múltiple111,114. De las tres, la imputación múltiple es la más usada y flexible, en especial cuando diversas variables tienen valores ausentes115. Los resultados que se obtienen al utilizar cualquiera de estas tres opciones deben compararse con los derivados de análisis de casos completos, y comentar las diferencias importantes. La plausibilidad de las suposiciones realizadas en análisis con datos ausentes generalmente no puede verificarse. En particular, es imposible probar que los datos son ausentes al azar más que ausentes no aleatoriamente. Por tanto, tales análisis son mejor apreciados con base en el análisis de sensibilidad (véanse los puntos 12e y 17).
“En programas de tratamiento con seguimiento activo, aquellos que se perdieron en el seguimiento presentaron en la determinación basal un recuento similar de células CD4 que aquellos con seguimiento a un año (mediana de 115 células por μl y 123 células por μl), mientras que los pacientes que se perdieron en el seguimiento en programas sin procedimientos de seguimiento activo tuvieron recuentos de CD4 considerablemente más bajos que los que se siguieron (mediana de 64 células por μl y 123 células por μl). (…) Los programas de tratamiento con seguimiento pasivo se excluyeron de los análisis subsecuentes”116.
ExplicaciónLos estudios de cohortes se analizan usando métodos de tablas de vida u otros enfoques basados en las personas-tiempo de seguimiento y en el tiempo para desarrollar la enfermedad de interés. Se asume que en los individuos que permanecen libres de la enfermedad al final del periodo de observación, la cantidad de tiempo del seguimiento no se relaciona con la probabilidad de desarrollar el resultado. Éste será el caso si el seguimiento concluye en una fecha fija o a una edad concreta. La pérdida durante el seguimiento ocurre cuando los participantes abandonan el estudio antes de esa fecha, lo cual puede afectar la validez del estudio si la pérdida del seguimiento ocurre selectivamente en los individuos expuestos o en personas con alto riesgo de desarrollar la enfermedad (“censura informativa”). En el ejemplo anterior, los pacientes perdidos durante el seguimiento en programas de tratamiento sin seguimiento activo tenían menos células CD4 colaboradoras que aquellos que permanecieron bajo observación y que por consiguiente presentaban un riesgo más alto de morir116.
Es importante distinguir a las personas que finalizan el estudio de aquellas que se pierden durante el seguimiento. Desafortunadamente, el programa estadístico no suele distinguir entre las dos situaciones: en ambos casos el tiempo de seguimiento es suspendido automáticamente (“censurado”) al final del periodo de observación. Por lo tanto, los investigadores necesitan decidir, idealmente en la fase de planificación del estudio, cómo manejarán las pérdidas durante el seguimiento. Cuando se pierden pocos pacientes, los investigadores pueden excluir a los individuos con seguimiento incompleto o tratarlos como si hubieran abandonado con vida en el momento de la pérdida o al final del estudio. Recomendamos a los autores que indiquen cuántos pacientes se perdieron durante el seguimiento y qué estrategias de censura utilizaron.
12 (d). Estudios de casos y controles: si procede, explique cómo se parearon casos y controlesEjemplo“Empleamos la prueba McNemar, la prueba t para muestras pareadas y el análisis de regresión logística condicional para comparar la ocurrencia de embolias cerebrales espontáneas, enfermedad carotídea y desviación de la circulación venosa a la arterial en los pacientes con demencia y en sus controles pareados por factores de riesgo cardiovascular” 117.
ExplicaciónEn los estudios de casos y controles pareados individualmente, el análisis crudo de la odds ratio, ignorando el emparejamiento, suele sesgar la estimación hacia la unidad (véase el Recuadro 2). Por lo tanto, es necesario un análisis pareado. Intuitivamente esto puede entenderse como un análisis estratificado: cada caso se ve como un estrato con su conjunto de controles pareados. El análisis se basa en considerar si el caso está expuesto más a menudo que los controles, a pesar de ser muy parecidos respecto a las variables de pareamiento. Los investigadores pueden hacer tal análisis estratificado mediante el método de Mantel-Haenszel en una tabla “pareada” de 2 por 2. En su forma más simple, la odds ratio se convierte en la razón de los pares discordantes para la variable de exposición. Si el emparejamiento se hizo por variables como la edad y el sexo, que son atributos universales, el análisis no requiere retener el pareamiento individual, persona a persona, y un simple análisis por categorías de edad y sexo es suficiente50. Sin embargo, para otras variables de pareamiento, como en el vecindario, la hermandad o la amistad, cada conjunto pareado debe ser considerado su propio estrato.
En los estudios pareados individualmente, el método de análisis más usado es la regresión logística condicional, en la cual se consideran juntos cada caso y sus controles. El método condicional es necesario cuando el número de controles varía entre los casos, y cuando se require ajustar el modelo por otras variables además de las de pareamiento. Para permitir a los lectores juzgar si en el análisis se tuvo en cuenta apropiadamente el diseño pareado, recomendamos que los autores describan con detalle los métodos estadísticos que emplearon para analizar los datos. Si al tener en cuenta el pareamiento tiene un efecto pequeño en las estimaciones, los autores pueden optar por presentar un análisis no pareado.
12 (d). Estudios transversales: si procede, especifique cómo se tiene en cuenta en el análisis la estrategia de muestreoEjemplo“Se calcularon los errores estándar (EE) usando el método de expansión de Taylor para estimar los errores de muestreo de los estimadores, basados en el diseño de muestra complejo. (…) Se encontró que el efecto de diseño general para la presión sanguínea diastólica fue de 1,9 para los hombres y 1,8 para las mujeres, y para la presión sistólica fue de 1,9 para los hombres y 2,0 para las mujeres118.
ExplicaciónLa mayoría de los estudios transversales utilizan una estrategia de muestreo preespecificada para seleccionar a los participantes de una población fuente. El muestreo puede ser más complejo que meramente tomar una muestra aleatoria simple; puede incluir varias etapas y grupos de participantes (por ejemplo, en distritos o pueblos). La estratificación proporcional puede asegurar que los subgrupos con una característica específica estén representados correctamente. La estratificación desproporcionada puede ser útil para sobremuestrear un subgrupo de particular interés.
Una asociación estimada basada en una muestra compleja puede ser más o menos precisa que la derivada de una muestra aleatoria simple. Se deben corregir las medidas de precisión, como el error estándar o el intervalo de confianza, usando el efecto de diseño, una medida de razón que describe cuánta precisión se gana o se pierde si se usa una estrategia de muestreo más compleja en lugar de un muestreo aleatorio simple119. La mayoría de las técnicas de muestreo complejas disminuyen la precisión, resultando en un efecto de diseño mayor de 1.
Aconsejamos que los autores expongan claramente el método empleado para ajustar por las estrategias de muestreo complejas, de modo que los lectores puedan entender cómo el método de muestreo elegido influyó en la precisión de las estimaciones obtenidas. Por ejemplo, con muestras conglomeradas, el intercambio implícito entre una recogida de datos más fácil y una pérdida de precisión es transparente si se indica el efecto de diseño. En el ejemplo, el efecto de diseño calculado, de 1,9 para los hombres, indica que el tamaño de la muestra real necesitaría ser 1,9 veces mayor que con el muestreo aleatorio simple para que las estimaciones resultantes fueran igualmente precisas.
12 (e). Describa los análisis de sensibilidadEjemplo“Debido a que tuvimos una proporción relativamente alta de pacientes muertas «perdidas» con datos insuficientes (38/148=25,7%) en comparación con las pacientes vivas (15/437=3,4%) (…), es posible que esto sesgara los resultados. Por consiguiente, se llevó a cabo un análisis de sensibilidad. Asumimos que la proporción de mujeres que usan anticonceptivos orales en el grupo del estudio se aplica a todas (19,1% para muertas y 11,4% para pacientes vivas), y entonces se consideraron dos posibilidades extremas: que todas las pacientes perdidas expuestas usaron píldoras de segunda generación o que todas usaron píldoras de tercera generación”120.
ExplicaciónLos análisis de sensibilidad son útiles para investigar si los resultados principales son consistentes o no con los obtenidos con estrategias o suposiciones de análisis alternativas121. Los problemas que pueden examinarse incluyen los criterios para la inclusión en los análisis, las definiciones de exposiciones o resultados122, qué variables de confusión requieren ajustarse, el manejo de datos ausentes120,123, el posible sesgo de selección o los sesgos derivados de la medida imprecisa o inconsistente de la exposición, la enfermedad y otras variables, así como decisiones de análisis específicas, como el tratamiento de las variables cuantitativas (ver el punto 11). Es creciente el empleo de métodos sofisticados para modelar simultáneamente la influencia de varios sesgos o suposiciones124–126.
En 1959, Cornfield et al mostraron que un riesgo relativo de 9 para fumadores de cigarrillos y cáncer de pulmón era sumamente improbable que se debiera a cualquier confusor concebible, debido a que el confusor necesitaría prevalecer por lo menos nueve veces más en los fumadores que en los no fumadores127. Este análisis no excluye la posibilidad de que un factor estuviera presente, pero identifica el predominio que tal factor necesitaría tener. La misma aproximación se utilizó para identificar probables factores confusores que podrían explicar la asociación entre la leucemia en la niñez y el vivir cerca de líneas de fuerza eléctrica128. Generalmente los análisis de sensibilidad pueden usarse para identificar el grado de confusión, el sesgo de selección o el sesgo de información requeridos para distorsionar una asociación. Poco conocido, un uso importante del análisis de sensibilidad es cuando un estudio muestra una asociación pequeña o nula entre una exposición y un resultado, y es plausible que estén ocurriendo confusión o sesgos hacia el valor nulo.
ResultadosLa sección de resultados debe hacer un claro recuento de lo que se encontró, del reclutamiento de los participantes, de la descripción de la población del estudio y de los principales resultados del análisis. Ha de estar libre de interpretaciones e ideas que reflejen las opiniones y los puntos de vista de los autores.
13. Participantes13 (a). Indique el número de participantes en cada fase del estudio; p. ej., número de participantes elegibles, analizados para ser incluidos, confirmados elegibles, incluidos en el estudio, los que tuvieron un seguimiento completo y los analizadosEjemplo
“De la muestra de 105 bares y tabernas, 13 establecimientos ya no funcionaban como tales y 9 se localizaban en restaurantes, quedando entonces 83 negocios elegibles. En 22 casos, el propietario no pudo ser localizado por teléfono después de por lo menos seis intentos. Los propietarios de 36 bares rehusaron participar en el estudio. (…) Los 25 bares y tabernas que participaron empleaban a 124 camareros, 67 de ellos trabajaban por lo menos 24 horas a la semana. Cincuenta y cuatro de los camareros con horario diurno (81%) completaron la entrevista y la espirometría basal; 53 de ellos (98%) terminaron el seguimiento”129.
ExplicaciónLa información detallada sobre el proceso de reclutamiento de los participantes del estudio es importante por varias razones. Los incluidos en un estudio a menudo difieren de la población diana a la cual se aplican los resultados. Esto puede resultar en estimaciones de la prevalencia o la incidencia que no reflejan lo que ocurre en la base poblacional. Por ejemplo, la gente que aceptó participar en una encuesta por correo sobre el comportamiento sexual asistía a la iglesia con menor frecuencia, tenía actitudes sexuales menos conservadoras y menor edad en su primera relación sexual, y era más probable que fumara y bebiera alcohol que la gente que rehusó participar130. Estas diferencias sugieren que las encuestas por correo pueden sobrestimar actitudes liberales y actividad sexual en la población. Tal sesgo de respuesta (véase el Recuadro 3) puede distorsionar asociaciones exposición-enfermedad si las asociaciones difieren entre los elegibles para el estudio y los incluidos. Otro ejemplo es la asociación encontrada entre una corta edad materna y el desarrollo de leucemia en los descendientes, que se ha observado en algunos estudios de casos y controles131,132 y ha sido explicada por la participación diferenciada de mujeres jóvenes en el grupo de casos y el grupo de controles. Las mujeres jóvenes con niños sanos era menos probable que participaran que las madres jóvenes con niños enfermos133. Si bien la baja participación no afecta necesariamente la validez de un estudio, la información clara sobre la participación y las razones de la no participación son esenciales. Del mismo modo, como no hay definiciones globalmente aceptadas sobre participación, respuesta o tasa de seguimiento, los lectores necesitan entender cómo los autores calculan tales proporciones134.
Idealmente los investigadores deben especificar el número de individuos considerados en cada fase del reclutamiento de los participantes del estudio y la selección de la base poblacional para la inclusión de los datos de los participantes en el análisis. Dependiendo del tipo de estudio, se puede incluir el número de individuos considerados elegibles, el número determinado por elegibilidad, el número incluido en el estudio, el número examinado, el número seguido y el número incluido en el análisis. Si el muestreo de los participantes del estudio se realiza en dos o más etapas, como en el ejemplo de arriba (muestreo multietápico), se puede requerir la información sobre diversas unidades de muestreo. En estudios de casos y controles, aconsejamos que los autores indiquen el flujo de participantes por separado para el grupo de casos y el de controles135. A veces los controles se pueden seleccionar de varias fuentes, incluyendo por ejemplo los pacientes hospitalizados y los habitantes de la comunidad. En tal caso recomendamos un recuento separado del número de participantes para cada tipo de grupo control. Olson et al. propusieron directrices útiles para informar sobre los controles reclutados mediante selección aleatoria por número de teléfono y otros métodos136.
Un trabajo reciente137 sobre estudios epidemiológicos publicados en 10 revistas de epidemiología general, salud pública y medicina, encontró que la información respecto a la participación fue proporcionada en 47 de 107 estudios de casos y controles (59%), 49 de 154 estudios de cohortes (32%) y 51 de 86 estudios transversales (59%). La información incompleta o ausente respecto a la participación o la no participación en estudios epidemiológicos también ha sido documentada en otros dos artículos4,5. Finalmente, hay pruebas de que la participación en estudios epidemiológicos puede haber disminuido en las últimas décadas 137,138, lo que subraya la necesidad de informes transparentes139.
13 (b). Describa las razones de la pérdida de participantes en cada faseEjemplo“Las principales razones de la no participación fueron que las participantes estaban demasiado enfermas o habían muerto antes de la entrevista (30% de los casos, <1% de los controles), sin respuesta (2% de los casos, 21% de los controles), rehusaron (10% de los casos, 29% de los controles) y otras razones (negativa de participar del médico especialista o médico de familia, no hablar inglés, problemas mentales) (7% de los casos, 5% de los controles)”140.
ExplicaciónLa explicación de las razones por las que la mayoría de la gente no participó en un estudio, o de por qué fueron excluidos del análisis estadístico, ayuda a los lectores a juzgar si la población estudiada era representativa de la base poblacional y si posiblemente se introdujo un sesgo. Por ejemplo, en una encuesta transversal de salud, la no participación debida a razones no relacionadas con el estado de salud (por ejemplo, la carta de invitación no fue entregada porque la dirección era incorrecta) afectará la precisión de las estimaciones, pero probablemente no introducirá un sesgo. Por el contrario, si muchos individuos optan por no participar debido a enfermedad o a percepción de buena salud, los resultados pueden subestimar o sobrestimar la prevalencia de la mala salud en la población.
13 (c). Considere el uso de un diagrama de fujoEjemploUn diagrama de flujo informativo y bien estructurado puede mostrar fácil y claramente la información que, de otra manera, puede requerir una descripción muy larga142, como en el ejemplo anterior. Un diagrama útil puede incluir los principales resultados, tales como el número de acontecimientos para el resultado primario. Recomendamos el uso de diagramas de flujo, particularmente para los estudios observacionales complejos, pero no proponemos un formato específico para ellos.
14Datos descriptivos14 (a). describa las características de los participantes en el estudio (p. ej., demográficas, clínicas, sociales) y la información sobre las exposiciones y los posibles factores de confusiónEjemplo
Tabla adaptada de Osella et al143.
| Características de la base poblacional en el momento del reclutamiento. Castellana G (Italia), 1985–1986 | |||
| VHC negativo | VHC positivo | Desconocido | |
| n=1458 | n=511 | n=513 | |
| Sexo (%) | |||
| Hombres | 936 (64%) | 296 (58%) | 197 (39%) |
| Mujeres | 522 (36%) | 215 (42%) | 306 (61%) |
| Media de la edad al inicio (DE) | 45,7(10,5) | 52,0 (9,7) | 52,5 (9,8) |
| Consumo diario de alcohol (%) | |||
| Nada | 250 (17%) | 129 (25%) | 119 (24%) |
| Moderadoa | 853 (59%) | 272 (53%) | 293 (58%) |
| Excesivob | 355 (24%) | 110 (22%) | 91 (18%) |
VHC: virus de la hepatitis C.
Los lectores necesitan la descripción de los participantes del estudio y de sus exposiciones para juzgar la posible generalización de los resultados. La información sobre los posibles confusores, incluyendo si se consideraron y cómo se determinaron, influye en los juicios sobre la validez del estudio. Aconsejamos a los autores resumir las variables continuas para cada grupo de estudio mediante la media y la desviación estándar, o si los datos tienen una distribución asimétrica, como sucede a menudo, la mediana y el rango en percentiles (por ejemplo, percentiles 25 y 75). Las variables nominales formadas por una pequeña cantidad de categorías (como las fases de la enfermedad I a IV) no se deben presentar como variables continuas; es preferible dar cantidades y proporciones para cada categoría (véase también el Recuadro 4). En estudios que comparan grupos, las características y los datos descriptivos se deben presentar por grupo, como en el ejemplo anterior.
Las medidas inferenciales, como los errores estándar y los intervalos de confianza, no se deben utilizar para describir la variabilidad de las características, y en las tablas descriptivas se deben evitar las pruebas de significación. Tampoco los valores p son un criterio apropiado para seleccionar por qué confusores ajustar el análisis; incluso pequeñas diferencias en un confusor que tenga un fuerte efecto sobre el resultado pueden ser importantes144,145.
En estudios de cohortes puede ser útil documentar cómo se relaciona una exposición con otras características y con los posibles confusores. Los autores podrían presentar esta información en una tabla con columnas para los participantes en dos o más categorías de exposición, que permita evaluar las diferencias con respecto a los confusores entre estas categorías.
En estudios de casos y controles, los posibles confusores no se pueden apreciar mediante la comparación de los casos y los controles. Los controles representan la población fuente y normalmente serán diferentes a los casos en muchos aspectos. Por ejemplo, en un estudio sobre anticonceptivos orales e infarto de miocardio, una muestra de mujeres jóvenes con infarto presentará más factores de riesgo para esa enfermedad que el grupo control, tales como colesterol sérico alto, tabaquismo y antecedentes familiares positivos146. Esto no influye en la evaluación del efecto de los anticonceptivos orales en tanto que su prescripción no estuvo guiada por la presencia de los factores de riesgo, por ejemplo debido a que estos factores de riesgo se establecieron después de ocurrido el evento (veáse también el Recuadro 5). En los estudios de casos y controles, el equivalente de comparar la presencia de posibles confusores (como se hace en las cohortes) entre expuestos y no expuestos se puede realizar explorando la población fuente de los casos: si el grupo control es suficientemente grande y representa a la población fuente, los controles expuestos y no expuestos se pueden comparar con respecto a los posibles confusores121,147.
14 (b). Indique el número de participantes con datos ausentes en cada variable de interésEjemploTabla adaptada de Hay et al141.
| Puntos sintomáticos terminales empleados en el análisis de supervivencia | |||
| Tos | Disnea | Somnolencia | |
| Síntoma resuelto | 201 (79%) | 138 (54%) | 171 (67%) |
| Censurado | 27 (10%) | 21 (8%) | 24 (9%) |
| Nunca sintomático | 0 | 46 (18%) | 11 (4%) |
| Datos ausentes | 28 (11%) | 51 (20%) | 50 (20%) |
| Total | 256 (100%) | 256 (100%) | 256 (100%) |
Puesto que los datos ausentes pueden sesgar o afectar la generalización de los resultados, los autores deben informar a los lectores sobre la cantidad de datos perdidos para las exposiciones, los posibles confusores y otras características importantes de los pacientes (véanse también el punto 12c y el Recuadro 6). En un estudio de cohortes, los autores deben especificar la cantidad de pérdidas durante el seguimiento (con sus razones), pues un seguimiento incompleto puede sesgar los hallazgos (veánse también los puntos 12d y 13)148. Recomendamos a los autores usar tablas y figuras para enumerar los datos ausentes.
14 (c). Estudios de cohortes: resuma el periodo de seguimiento (p. ej., promedio y total)Ejemplo“Durante el seguimiento de 4366 personas-año (mediana 5,4, máximo 8,3 años), 265 sujetos fueron diagnosticados como dementes, incluyendo 202 con enfermedad de Alzheimer”149.
ExplicaciónLos lectores deben saber la duración y la extensión del seguimiento de los datos disponibles acerca del evento resultado. Los autores pueden presentar un resumen del promedio de seguimiento incluyendo la media, la mediana o ambas. La media permite al lector calcular el número total de personas-año multiplicándola por el número de participantes en el estudio. También se deben presentar los tiempos mínimo y máximo, o los percentiles de la distribución, para mostrar a los lectores la dispersión del tiempo de seguimiento. Deben especificar el total personas-año de seguimiento o alguna indicación de la proporción de datos que fueron capturados con respecto al total posible148. Toda esta información sobre los participantes se debe presentar separadamente en dos o más categorías de exposición. Casi la mitad de 132 artículos publicados en revistas sobre cáncer (en su mayoría estudios de cohortes) no presentaban algún resumen de la duración del seguimiento37.
15. Datos de las variables de resultadoEstudios de cohortes: indique el número de eventos resultado o bien proporcione medidas de resumen a lo largo del tiempoEjemplo
Tabla adaptada de Kengeya-Kayondo et al.150
Tasas de seroconversión VIH-1 por variables sociodemográficas seleccionadas: 1990–1993
| Variable | Personas-año | N.o seroconvertidos | Tasa/1000 personas-año (IC95%) |
| Año | |||
| 1990 | 2197,5 | 18 | 8,2 (4,4–12,0) |
| 1991 | 3210,7 | 22 | 6,9 (4,0–9,7) |
| 1992 | 3162,6 | 18 | 5,7 (3,1–8,3) |
| 1993 | 2912,9 | 26 | 8,9 (5,5–12,4) |
| 1994 | 1104,5 | 5 | 4,5 (0,6–8,5) |
| Tribu | |||
| Bugandesa | 8433,1 | 48 | 5,7 (4,1–7,3) |
| Otras ugandesas | 578,4 | 9 | 15,6 (5,4–25,7) |
| Ruandesa | 2318,6 | 16 | 6,9 (3,5–10,3) |
| Otra tribu | 866,0 | 12 | 13,9 (6,0–21,7) |
| Religión | |||
| Musulmana | 3313,5 | 9 | 2,7 (0,9–4,5) |
| Otra | 8882,7 | 76 | 8,6 (6,6–10,5) |
IC95%: intervalo de confianza del 95%.
Tabla adaptada de Mastrangelo et al151.
| Exposición entre casos de cirrosis hepática y controles | ||
| Casos (n=40) | Controles (n=139) | |
| Cloruro de vinilo monómero (exposición acumulada: ppm×años) | ||
| <160 | 7 (18%) | 38 (27%) |
| 160–500 | 7 (18%) | 40 (29%) |
| 500–2500 | 9 (23%) | 37 (27%) |
| >2500 | 17 (43%) | 24 (17% |
| Consumo de alcohol (g/día) | ||
| <30 | 1 (3%) | 82 (59%) |
| 30–60 | 7 (18%) | 46 (33%) |
| >60 | 32 (80%) | 11 (8%) |
| AgsHB/VHC | ||
| Negativo | 33 (83%) | 136 (98%) |
| Positivo | 7 (18%) | 3 (2%) |
AgsHB: antígeno de superficie de la hepatitis B; VHC: virus de la hepatitis C.
Estudios transversales: indique el número de eventos resultado o bien proporcione medidas resumen.
EjemploTabla adaptada de Salo et al.152.
| Prevalencia de asma actual y de fiebre del heno diagnosticadas por nivel promedio de antígeno de Alternaria alternata en el hogar | ||||
| Nivel categorizado de Alternariaa | Asma actual | Fiebre del heno diagnosticada | ||
| n | Prevalenciab (IC95%) | n | Prevalenciab (IC95%) | |
| 1er tercil | 40 | 4,8 (3,3–6,9) | 93 | 16,4 (13,0–20,5) |
| 2o tercil | 61 | 7,5 (5,2–10,6) | 122 | 17,1 (12,8–22,5) |
| 3er tercil | 73 | 8,7 (6,7–11,3) | 93 | 15,2 (12,1–18,9) |
Antes de establecer la posible asociación entre las exposiciones (factores de riesgo) y los resultados, los autores deben proporcionar los datos descriptivos relevantes. Puede ser posible y significativo presentar medidas de asociación en la misma tabla que muestra los datos descriptivos (véase el punto 14a). En un estudio de cohortes con eventos como resultados, indique el número de eventos para cada resultado de interés. Considere especificar la tasa del evento por personas-año de seguimiento. Si el riesgo de un evento cambia durante el tiempo de seguimiento, presente las cifras y las tasas de eventos en intervalos apropiados del seguimiento, como una tabla de vida de Kaplan-Meier o de manera gráfica. Puede ser preferible realizar gráficas de incidencia acumulada que partan de 0% en lugar de que disminuyan a partir del 100%, especialmente si la tasa del evento es menor, por ejemplo, del 30%153. Considere presentar esta información por separado para los participantes en diversas categorías de la exposición de interés. Si un estudio de cohortes está investigando otros resultados relacionados con el tiempo (p.ej., marcadores cuantitativos de una enfermedad, como la presión sanguínea), presente medidas resumen apropiadas (por ejemplo, medias y desviaciones estándar) a lo largo del tiempo, quizás en una tabla o una figura.
Para los estudios transversales recomendamos presentar el mismo tipo de información sobre eventos resultado prevalentes o medidas de resumen. Para los estudios de casos y controles se indicarán las exposiciones para los casos y los controles por separado, como frecuencias o medidas resumen cuantitativas154. Para todos los diseños, también puede resultar útil tabular los eventos resultado o las exposiciones continuas en categorías, incluso si los datos no se analizan como tales.
16. Resultados principales16 (a). Proporcione estimaciones no ajustadas y, si procede, ajustadas por factores de confusión, así como su precisión (p. ej., intervalos de confianza del 95%). Especifique los factores de confusión por los que se ajusta y las razones para incluirlosEjemplo 1“Inicialmente consideramos las siguientes variables como posibles confusores mediante un análisis estratificado de Mantel-Haenszel: (…) las variables que incluimos en los modelos de regresión logística finales fueron aquellas (…) que producían un cambio del 10% en la odds ratio después del ajuste de Mantel-Haenszel”155.
Ejemplo 2Tabla adaptada de Tilhonen et al156.
Tasas relativas de rehospitalización por tratamiento en pacientes de atención primaria después de la primera hospitalización por esquizofrenia o un trastorno esquizoafectivo
| Tratamiento | N.o de recaídas | Personas-año | Tasa relativa bruta (IC95%) | Tasa relativa ajustada (IC95%) | Tasa relativa completamente ajustada (IC95%) |
| Perfenazina | 53 | 187 | 0,41 (0,29–0,59) | 0,45 (0,32–0,65) | 0,32 (0,22–0,49) |
| Olanzapina | 329 | 822 | 0,59 (0,45–0,75) | 0,55 (0,43–0,72) | 0,54 (0,41–0,71) |
| Clozapina | 336 | 804 | 0,61 (0,47–0,79) | 0,53 (0,41–0,69) | 0,64 (0,48–0,85) |
| Clorprotixeno | 79 | 146 | 0,79 (0,58–1,09) | 0,83 (0,61–1,15) | 0,64 (0,45–0,91) |
| Tioridazina | 115 | 201 | 0,84 (0,63–1,12) | 0,82 (0,61–1,10) | 0,70 (0,51–0,96) |
| Perfenazina | 155 | 327 | 0,69 (0,58–0,82) | 0,78 (0,59–1,03) | 0,85 (0,63–1,13) |
| Risperidona | 343 | 651 | 0,77 (0,60–0,99) | 0,80 (0,62–1,03) | 0,89 (0,69–1,16) |
| Haloperidol | 73 | 107 | 1,00 | 1,00 | 1,00 |
| Clorpromazina | 82 | 127 | 0,94 (0,69–1,29) | 0,97 (0,71–1,33) | 1,06 (0,76–1,47) |
| Levomepromazina | 52 | 63 | 1,21 (0,84–1,73) | 0,82 (0,58–1,18) | 1,09 (0,76–1,57) |
| Fármacos no antipsicóticos | 2.248 | 3.362 | 0,98 (0,77–1,23) | 1,01 (0,80–1,27) | 1,16 (0,91–1,47) |
Ajustado por sexo, año, edad al inicio del seguimiento, número de recaídas previas, duración de la primera hospitalización y duración del seguimiento (columna ajustada), y adicionalmente por una calificación de la propensión a iniciar un tratamiento diferente al haloperidol (columna totalmente ajustada).
En muchas situaciones los autores pueden presentar los resultados del análisis sin ajustar o mínimamente ajustados, y análisis completamente ajustados. Recomendamos presentar los análisis no ajustados junto con los datos principales, por ejemplo el número de casos y de controles expuestos y no expuestos. Esto permite que el lector comprenda los datos que están detrás de las medidas de la asociación (véase también el punto 15). Para los análisis ajustados, indique el número de personas en el análisis, ya que este número puede diferir debido a valores ausentes en las covariables (véase también el punto 12c). Los estimadores se deben proporcionar con intervalos de confianza.
Los lectores pueden comparar las medidas de asociación no ajustadas con las ajustadas por posibles confusores y juzgar cuánto se modifican y en qué dirección. Pueden pensar que los resultados “ajustados” equivalen a la parte causal de la medida de asociación, pero estos resultados no necesariamente están libres de un error de muestreo aleatorio, un sesgo de selección o una confusión residual (véase el Recuadro 5). Así, se debe tener mucho cuidado cuando se interpreten los resultados ajustados, ya que su validez a menudo depende crucialmente del conocimiento completo de los confusores importantes, de su determinación precisa y de la especificación apropiada en el modelo estadístico (véase también el punto 20)157,158.
Los autores deben explicar todos los posibles confusores considerados y los criterios para excluir o incluir variables en los modelos estadísticos. Las decisiones acerca de la exclusión o la inclusión de variables se deben guiar por el conocimiento o por suposiciones explícitas sobre las relaciones causales. Las decisiones incorrectas pueden introducir sesgos, por ejemplo incluyendo las variables que están en la línea causal entre la exposición y la enfermedad (a menos que el propósito sea evaluar qué parte del efecto está producida por la variable intermediaria). Si la decisión para incluir una variable en el modelo se basó en un cambio en el estimador, es importante indicar qué cambio se consideró suficientemente importante para justificar su inclusión. Si se empleó una estrategia de modelado mediante “eliminación hacia atrás” o “inclusión hacia adelante” para la selección de los confusores, explique el proceso e indique el nivel de significación para rechazar la hipótesis nula en ausencia de confusores. Cabe destacar que nosotros, al igual que otros autores, no recomendamos seleccionar los confusores basándose únicamente en la significación estadística147,159,160.
Estudios recientes sobre la calidad de los artículos de estudios epidemiológicos han hallado que la mayoría especifican los intervalos de confianza4. Sin embargo, pocos autores explican la selección de sus variables confusoras4,5.
16 (b). Si categoriza variables continuas, describa los límites de los intervalosEjemploTabla adaptada de Sagiv et al161.
ExplicaciónCategorizar datos continuos tiene varias implicaciones importantes para el análisis (véase el Recuadro 4) y también afecta la presentación de los resultados. Empleando tablas, los resultados se deben mostrar para cada categoría de la exposición, por ejemplo como número de personas en riesgo, personas-tiempo en riesgo, y si es relevantes por separado para cada grupo (p.ej., los casos y los controles). Los detalles de las categorías usadas pueden ayudar a la comparación de estudios y a los metaanálisis. Si los datos se han agrupado usando puntos de corte convencionales, como los límites del índice de masa corporal162, los límites grupales (p.ej., los intervalos de valores) se pueden derivar fácilmente, con excepción de las categorías más altas y más bajas. Si se utilizan categorías derivadas de percentiles, los límites de la categoría no se pueden deducir de los datos. Como mínimo, los autores deben indicar los límites de la categoría; también es útil especificar el intervalo de los datos y la media o la mediana dentro de las categorías.
16 (c). Si fuera pertinente, valore acompañar las estimaciones del riesgo relativo con estimaciones del riesgo absoluto para un periodo de tiempo relevanteEjemplo“Se estimó que el uso de terapia hormonal sustitutiva durante 10 años resulta en cinco (IC95%: 3–7) cánceres de mama adicionales por cada 1000 usuarias de preparaciones de estrógenos solos y en 19 (15–23) cánceres adicionales por 1000 usuarias de combinaciones de estrógenos-progestágenos’’163.
ExplicaciónLos resultados de los estudios que investigan la asociación entre una exposición y una enfermedad se presentan comúnmente en términos relativos, como razones de riesgos, de tasas o de odds (véase el Recuadro 8). Las medidas relativas indican la fuerza de la asociación entre una exposición y una enfermedad. Si el riesgo relativo está lejos de 1, es menos probable que la asociación se deba a un factor de confusión164,165. Los efectos relativos o las asociaciones tienden a ser más consistentes a lo largo de estudios y de poblaciones que las medidas absolutas, pero lo que a menudo tiende a ser el caso puede ser irrelevante en una situación particular. Por ejemplo, se obtuvieron riesgos relativos similares para los factores de riesgo cardiovasculares clásicos para los hombres que vivían en Irlanda del Norte, Francia, Estados Unidos y Alemania, a pesar de que el riesgo subyacente de enfermedad cardiaca coronaria varía sustancialmente entre estos países 166,167. En cambio, en un estudio sobre la hipertensión como factor de riesgo para la mortalidad por enfermedad cardiovascular, los datos eran más compatibles con una diferencia de tasas constante que con una razón de tasas constante168.
Los modelos estadísticos que más se utilizan, incluyendo las regresiones logística169 y proporcional de riesgos (Cox)170, se basan en medidas de razón. En estos modelos se distinguen fácilmente las desviaciones de las medidas de efecto con respecto a la constante. Sin embargo, las medidas que evalúan desviaciones de la aditividad con respecto a las diferencias de riesgo, como el exceso de riesgo relativo de la interacción (RERI, véanse el punto 12b y el Recuadro 8), se pueden estimar a partir de los modelos basados en medidas de razón.
En muchas circunstancias, el riesgo absoluto asociado a una exposición es de mayor interés que el riesgo relativo. Por ejemplo, si se centra la atención en los efectos nocivos de un fármaco, se deseará saber el número de casos adicionales por unidad de tiempo de uso (por ejemplo, días, semanas o años). El ejemplo presenta el número adicional de casos de cáncer de mama por cada 1000 mujeres que utilizaron terapia hormonal de reemplazo durante 10 años163. Medidas como el riesgo o la fracción atribuible poblacional pueden ser útiles para estimar qué proporción de la enfermedad se podría prevenir si se elimina la exposición. Estas medidas se deben presentar preferiblemente junto con una medida de incertidumbre estadística (por ejemplo, intervalos de confianza como en el ejemplo). Los autores deben ser conscientes de las fuertes suposiciones que se hacen en este contexto, incluyendo una relación causal entre un factor de riesgo y una enfermedad (véase también el Recuadro 7)171. Debido a la ambigüedad semántica y a la complejidad que implica, los autores deben indicar detalladamente qué métodos utilizaron para calcular los riesgos atribuibles, idealmente presentando las fórmulas usadas 172.
Medidas de asociación, efecto e impacto.
Los estudios observacionales sólo se pueden llevar a cabo para describir la magnitud y la distribución de un problema de salud en la población. Pueden investigar el número de personas que tienen una enfermedad en un momento particular (prevalencia) o que la desarrollan en un periodo de tiempo definido (incidencia). La incidencia se puede expresar como la proporción de gente que desarrolla la enfermedad (incidencia acumulada) o como la tasa por personas-tiempo de seguimiento (tasa de incidencia). Se emplean términos específicos para describir diversas incidencias; entre otros, tasa de mortalidad, tasa de natalidad, tasa de ataque y tasa de fatalidad de casos. Del mismo modo, los términos como prevalencia puntual y de periodo, prevalencia anual o del curso de la vida, se utilizan para describir diversos tipos de prevalencia30.
Otros estudios observacionales tratan relaciones de causa-efecto. Su objetivo es comparar el riesgo, la tasa o la prevalencia del evento de interés entre expuestos y no expuestos al factor de riesgo en investigación. Estos estudios a menudo estiman el “riesgo relativo”, el cual puede representar razones de riesgo (razones de incidencias acumuladas) o razones de tasas (razones de tasas incidencia).
En los estudios de casos y controles, sólo se incluye una fracción de la población base (los controles). Los resultados se expresan mediante odds ratio de las exposiciones entre casos y controles. Esta odds ratio aporta una estimación de la razón de riesgos o la razón de tasas en función del muestreo de casos y controles (véase también el Recuadro 7)175,176. La razón de prevalencias o la odds ratio de prevalencia de los estudios transversales pueden ser útiles en algunas situaciones177.
A menudo puede ser conveniente expresar los resultados tanto en términos relativos como en términos absolutos. Por ejemplo, en un estudio178 de médicos británicos, la tasa de incidencia de muertes por cáncer de pulmón a lo largo de un seguimiento de 50 años fue de 249 por 100.000 y año entre los fumadores, en comparación con 17 por 100.000 y año entre los no fumadores: una razón de tasas de 14,6 (249/17). Para la enfermedad cardiaca coronaria (ECC), las tasas correspondientes fueron de 1001 y 619 por 100.000 y año, una razón de tasas de 1,61 (1001/619). El efecto del tabaquismo sobre la mortalidad parece mucho más fuerte para el cáncer de pulmón que para la ECC. El cuadro cambia cuando consideramos los efectos absolutos de fumar: la diferencia en las tasas de incidencia fue de 232 por 100.000 y año (249–17) para el cáncer pulmonar y de 382 para la ECC (1001–619). Por lo tanto, entre los médicos que fumaban era más probable que su tabaquismo causara una muerte por ECC que por cáncer de pulmón.
¿Cuánta carga de la enfermedad se podría prevenir en una población eliminando una exposición? Se han publicado estimaciones globales para el caso del tabaquismo: según un estudio179, el 91% de todos los cánceres de pulmón, el 40% de las ECC y el 33% de todas las muertes de hombres en el año 2000 se atribuyeron a este factor179. Generalmente se define la fracción atribuible poblacional como la proporción de casos causados por una exposición particular, pero existen varios conceptos (ninguna terminología unificada), y a veces se utilizan aproximaciones incorrectas para ajustar por otros factores172,180. ¿Cuáles son las implicaciones para los artículos? Las medidas relativas hacen énfasis en la fuerza de una asociación, y son las más útiles de la investigación etiológica. Si se documenta una relación causal con una exposición y las asociaciones se interpretan como efectos, las estimaciones del riesgo relativo se pueden traducir en medidas convenientes del riesgo absoluto con el fin de calcular el posible efecto de las políticas de salud pública (véase el punto 16c)181. Sin embargo, los autores deben ser conscientes de las fuertes suposiciones que se hacen en este contexto171. Se requiere cuidado a la hora de decidir qué concepto y qué método son apropiados para una situación particular.
Un estudio reciente de los resúmenes de 222 artículos publicados en las revistas médicas más importantes encontró que en el 62% de los resúmenes de ensayos aleatorizados que incluyeron una medida de razón se presentaban los riesgos absolutos, en comparación con sólo el 21% de los resúmenes de los estudios de cohortes173. Una búsqueda de texto libre en Medline de 1966 a 1997 mostró que 619 artículos mencionaron riesgos atribuibles en el título o en el resumen, en comparación con 18.995 que usaban solamente medidas de riesgo relativo u odds ratios, es decir, una proporción de 1 a 31174.
17. Otros análisis: describa otros análisis efectuados (de subgrupos, interacciones o sensibilidadEjemplo 1Ejemplo 2Tabla adaptada de Wei et al184.
| Sensibilidad de la razón de tasas para un evento cardiovascular con respecto a un confusor no medido | |||
| Prevalencia del confusor binario no medido en el grupo expuesto (%) | Prevalencia del confusor binario no medido en el grupo de comparación (%) | Razón de tasas del confusor binario no medido | Razón de tasas para el nivel alto de exposicióna (IC95%) |
| 90 | 10 | 1,5 | 1,20 (1,01–0,59) |
| 90 | 50 | 1,5 | 1,43 (1,22–1,67) |
| 50 | 10 | 1,5 | 1,39 (1,18–1,63) |
| 90 | 10 | 2 | 0,96 (0,81–1,13) |
| 90 | 50 | 2 | 1,27 (1,11–1,45) |
| 50 | 10 | 2 | 1,21 (1,03–1,42) |
| 90 | 50 | 3 | 1,18 (1,01–1,38) |
| 50 | 10 | 3 | 0,99 (0,85–1,16) |
| 90 | 50 | 5 | 1,08 (0,85–1,26) |
IC95%: intervalo de confianza al 95%.
Además del análisis principal, en los estudios observacionales a menudo se hacen otros análisis. Pueden referirse a subgrupos específicos, a la posible interacción de factores de riesgo, al cálculo de riesgos atribuibles o al uso de definiciones alternativas de las variables en estudio durante el análisis de sensibilidad.
Hay un debate sobre los peligros asociados al análisis de subgrupos, y en general con la multiplicidad de análisis4,104. En nuestra opinión, también hay una tendencia muy acentuada a buscar evidencias de asociaciones específicas en subgrupos o de modificación del efecto, cuando los resultados globales sugieren poco o ningún efecto. Por otra parte, puede ser valioso explorar si una asociación global parece consistente en varios subgrupos, preferiblemente los preespecificados, en especial cuando un estudio es lo suficiente grande como para tener bastantes datos en cada subgrupo. Un segundo tema de discusión son los subgrupos interesantes que aparecen durante el análisis de datos. Puede que sean hallazgos importantes, pero también puede que aparezcan por casualidad. Algunos argumentan que no es posible ni necesario informar al lector sobre todos los análisis de subgrupos llevados a cabo, ya que análisis futuros de otros datos indicarán en qué medida estos primeros y estimulantes resultados pasan la prueba del tiempo9. Nosotros recomendamos a los autores señalar qué análisis se planificaron y cuáles no (véanse también los puntos 4, 12b y 20). Esto permitirá que los lectores juzguen las implicaciones de la multiplicidad, considerando la posición del estudio respecto al continuo que va del descubrimiento a la verificación o a la refutación.
Una tercera cuestión de debate es cómo se deben evaluar los efectos conjuntos y las interacciones de los factores de riesgo: ¿en escalas aditivas o multiplicativas, o la escala se debe determinar por el modelo estadístico que mejor ajuste? (Véanse también el punto 12b y el Recuadro 8.) Una opción apropiada es indicar por separado el efecto de cada exposición, así como el efecto conjunto, si es posible en una tabla, como en el primer ejemplo de arriba183 o como en el estudio de Martinelli et al185. Esta tabla ofrece al lector suficiente información para evaluar tanto la interacción aditiva como la multiplicativa (en el Recuadro 8 se muestra cómo se hacen estos cálculos). Los intervalos de confianza para los efectos aislados y en conjunto pueden ayudar al lector a juzgar la potencia de los datos. Además, los intervalos de confianza de las medidas de interacción, como el exceso del riesgo relativo de la interacción (RERI), se relacionan con las pruebas de interacción o de homogeneidad. Un problema recurrente es que los autores utilizan comparaciones de valores p entre subgrupos, lo que lleva a suponer erróneamente una modificación del efecto. Por ejemplo, una asociación estadísticamente significativa en una categoría (hombres), pero no en la otra (mujeres), en sí misma no proporciona evidencia de la modificación del efecto. Del mismo modo, los intervalos de confianza para cada estimador concreto se utilizan a veces de forma inadecuada para inferir que no hay interacción cuando los intervalos se solapan. Se consigue una inferencia más válida evaluando directamente si la magnitud de una asociación difiere entre los subgrupos.
Interacción (modificación del efecto): el análisis de los efectos conjuntos.
Existe interacción cuando la asociación de una exposición con el riesgo de la enfermedad difiere en presencia de otra exposición. Un problema de la evaluación y la comunicación de interacciones es que el efecto de una exposición se puede medir de dos maneras: como un riesgo relativo (o razón de tasas) o como una diferencia de riesgo (o diferencia de tasas). El uso del riesgo relativo conduce a un modelo multiplicativo, mientras que el uso de la diferencia de riesgo corresponde a un modelo aditivo187,188. A veces se distingue entre la “interacción estadística”, que puede derivarse de un modelo multiplicativo o aditivo, y la “interacción biológica”, que se mide a partir de un modelo aditivo189. Sin embargo, los modelos aditivos y los multiplicativos no apuntan hacia un mecanismo biológico particular.
Independientemente del modelo elegido, el objetivo principal es entender cómo el efecto conjunto de dos exposiciones difiere de sus efectos separados (en ausencia de la otra exposición). La Red de Epidemiología del Genoma Humano (HuGENet) propuso un esquema para la presentación transparente de efectos separados y conjuntos, que permite evaluar diversos tipos de interacción183. Se emplearon datos del estudio sobre anticonceptivos orales y mutación del factor V de Leiden182 para explicar la propuesta, y este ejemplo también se ha empleado en el punto 17. Los anticonceptivos orales y la mutación del factor V de Leiden incrementan el riesgo de trombosis venosa; sus efectos separados y conjuntos se pueden calcular de la tabla 2×4 (véase el ejemplo 1 del punto 17), donde la odds ratio de 1 denota la línea basal de las mujeres sin el factor V de Leiden que no utilizan anticonceptivos orales.
Una dificultad es que los diseños de algunos estudios, como los de casos y controles, y varios modelos estadísticos, como los logísticos o de regresión de Cox, estiman riesgos relativos (o razones de tasas) e intrínsecamente conducen a un modelo multiplicativo. En estos casos, los riesgos relativos se pueden traducir a una escala aditiva. En el ejemplo 1 del punto 17, las odds ratios separadas son 3,7 y 6,9, mientras que la conjunta es 34,7. Cuando estos datos se analizan con un modelo multiplicativo, se espera una odds ratio conjunta de 25,7 (3,7×6,9). El efecto conjunto observado, de 34,7, es 1,4 mayor que el esperado en una escala multiplicativa (34,7/25,7). Esta cantidad (1,4) es la odds ratio de la interacción multiplicativa. Sería igual al antilogaritmo del coeficiente estimado de la interacción de un modelo de regresión logística. Con el modelo aditivo se espera que la odds ratio conjunta sea 9,6 (3,7+6,9−1). El efecto conjunto observado se aleja fuertemente de la aditividad: la diferencia es 25,1 (34,7−9,6). Cuando las odds ratios se interpretan como riesgos relativos (o razones de tasas), la última cantidad (25,1) es el exceso del riesgo relativo de la interacción (RERI)190. Esto se puede entender más fácilmente al imaginarse que el valor de referencia (equivalente a una odds ratio=1) representa una incidencia basal de trombosis venosa de, por ejemplo, 1/10.000 mujeres-año, que aumenta en presencia de exposiciones separadas y conjuntas.
Los análisis de sensibilidad son útiles para investigar la influencia de las decisiones que se toman durante el análisis estadístico, y para investigar la robustez de los hallazgos con respecto a los datos ausentes o a los posibles sesgos (véase también el punto 12b). Es necesario tener un criterio explícito acerca de la cantidad de información sobre tales análisis. Si se realizaron muchos análisis de sensibilidad, puede ser poco práctico presentar los resultados detallados de todos ellos. A veces puede ser suficiente señalar que se realizaron los análisis de sensibilidad y que fueron consistentes con los principales resultados presentados. La presentación detallada es más apropiada si el problema investigado es importante o si las estimaciones del efecto varían considerablemente59,186.
Pocock et al.4 encontraron que 43 de 73 artículos que presentaban estudios observacionales contenían análisis de subgrupos. La mayoría señalaba diferencias entre grupos, pero solamente ocho artículos presentaban una evaluación formal de la interacción (véase el punto 12(b)).
DiscusiónLa sección de la discusión trata los temas centrales de la validez y el significado del estudio191. Algunos trabajos han encontrado que las secciones de la discusión a menudo están dominadas por evaluaciones incompletas o sesgadas de los resultados del estudio y de sus implicaciones, así como con retórica que apoya los resultados de los autores192,193. Estructurar la discusión puede ayudar a los autores a evitar la especulación y la sobreinterpretación injustificadas de los resultados, y al mismo tiempo orientar a los lectores a lo largo del texto194,195. Por ejemplo, Annals of Internal Medicine196 recomienda que los autores estructuren la sección de la discusión presentando lo siguiente: 1) una breve sinopsis de los resultados clave; 2) una consideración de los posibles mecanismos y explicaciones; 3) una comparación con los resultados relevantes de otros estudios publicados; 4) las limitaciones del estudio; y 5) un breve apartado que resuma las implicaciones del trabajo para la práctica y la investigación. Otros han hecho sugerencias similares191,194. Los apartados sobre recomendaciones para la investigación y sobre las limitaciones del estudio deben relacionarse de forma estrecha uno con otro. Los investigadores deben sugerir modos de mejorar la investigación subsecuente más que simplemente señalar que “se requiere más investigación”197,198. Recomendamos que los autores estructuren sus apartados de la discusión, incluso empleando subtítulos convenientes.
18. Resultados clave: resuma los resultados principales de los objetivos del estudioEjemplo“Nuestra hipótesis era que pertenecer a una etnia minoritaria estaría asociado con un mayor riesgo de enfermedad cardiovascular (ECV), pero que la asociación se explicaría sustancialmente por el nivel socioeconómico (NSE). Esta hipótesis no se confirmó. Después de ajustar por la edad y por NSE, siguieron existiendo diferencias altamente significativas en el índice de masa corporal, la presión sanguínea, la diabetes y la inactividad física entre las mujeres blancas y las mujeres de raza negra, así como con las méxico-americanas. Además, encontramos grandes diferencias en los factores de riesgo para ECV por NSE, un hallazgo que ilustra la situación de alto riesgo tanto de las mujeres en la etnia minoritaria como de las mujeres blancas con NSE bajo”199.
ExplicaciónEs una buena práctica comenzar la discusión con un resumen breve de los principales hallazgos del estudio. Un resumen corto recuerda a los lectores los hallazgos principales y les ayuda a evaluar si las interpretaciones subsecuentes y las implicaciones mostradas por los autores están apoyadas por los hallazgos.
19. Limitaciones: discuta las limitaciones del estudio, teniendo en cuenta posibles fuentes de sesgo o de imprecisión. razone tanto sobre la dirección como sobre la magnitud de cualquier posible sesgoEjemplo“Dado que la frecuencia del consejo aumenta con el mayor grado de obesidad, nuestros estimadores pueden sobrestimar la verdadera prevalencia de la búsqueda de ayuda. Las encuestas telefónicas también pueden sobrestimar la verdadera prevalencia del consejo. Aunque las personas sin teléfono tienen similares grados de sobrepeso que las personas con teléfono, aquéllas sin este servicio tienden a ser menos educadas, un factor asociado con menos consejo en nuestro estudio. También llama la atención el posible sesgo causado por los que rechazaron participar, así como por los que rechazaron responder a las preguntas acerca del peso corporal. Además, debido a que los datos se recogieron transversalmente, no podemos inferir que el consejo precediera al intento del paciente de perder peso”200.
ExplicaciónLa identificación y la discusión de las limitaciones de un estudio son una parte esencial del artículo científico. Es importante no sólo identificar el origen de los sesgos y de la confusión que pueden afectar los resultados, sino también comentar la importancia relativa de los diferentes sesgos, incluyendo la dirección y la magnitud de cualquier posible sesgo (véanse el Recuadro 3 y el punto 9).
Los autores deben discutir también cualquier imprecisión de los resultados. Esta imprecisión puede surgir respecto a varios aspectos del estudio, incluyendo su tamaño (punto 10) y la medida de la exposición, los confusores y los resultados (punto 8). La incapacidad para medir con precisión los verdaderos valores de una exposición tiende a derivar en un sesgo hacia la unidad: cuanto menor sea la precisión en la medida del factor de riesgo, mayor será el sesgo. Este efecto se ha descrito como “atenuación”201,202 y más recientemente como “sesgo de dilución por la regresión”203. Sin embargo, cuando los factores de riesgo correlacionados se miden con diferentes niveles de imprecisión, el riesgo relativo ajustado asociado a ellos puede estar sesgado en la dirección o en contra de la unidad204–206.
Al comentar las limitaciones, los autores pueden comparar su estudio con otros de la literatura en términos de validez, generalización y precisión. Con este enfoque, cada estudio se puede ver como una contribución a la literatura, no como una base autónoma para la inferencia y la acción207. Sorprendentemente, la discusión de las limitaciones importantes de un estudio a veces se omite en los artículos publicados. Una encuesta entre los autores que habían publicado artículos de investigación original en la revista The Lancet encontró que los investigadores señalaban las debilidades importantes de los estudios en la encuesta, pero no en los artículos que habían publicado192.
20. Interpretación: proporcione una interpretación global prudente de los resultados considerando objetivos, limitaciones, multiplicidad de análisis, resultados de estudios similares y otras pruebas empíricas relevantesEjemplo“Cualquier explicación de una asociación entre muerte por infarto de miocardio y uso de anticonceptivos orales de segunda generación debe ser una conjetura. No hay evidencia publicada que sugiera un mecanismo biológico directo, y no hay otros estudios epidemiológicos con resultados relevantes. (…) El incremento en el riesgo absoluto es muy pequeño y probablemente se aplique predominantemente a fumadores. Debido a la falta de evidencia que lo confirme, y considerando que el análisis se basó en cifras relativamente pequeñas, se necesitan más pruebas al respecto. No recomendaríamos ningún cambio en la práctica de prescripción basándose en estos resultados”120.
ExplicaciónEl núcleo de la sección de la discusión es la interpretación de los resultados del estudio. La sobreinterpretación es común y de humanos; aun cuando nos esforzamos por ofrecer una evaluación objetiva, con frecuencia los revisores nos señalan que fuimos muy lejos en algunos aspectos. Cuando se interpreten los resultados, los autores deben considerar la naturaleza del estudio basándose en la verificación continua de los descubrimientos y en las posibles fuentes de sesgo, incluyendo las pérdidas durante el seguimiento y la no participación (ver puntos 9, 12 y 19). Se deben considerar adecuadamente el tema de la confusión (punto 16a) y los resultados relevantes del análisis de sensibilidad, así como el problema de la multiplicidad y el análisis de los diferentes subgrupos (punto 17). Los autores siempre deben tener en cuenta la confusión residual debida a variables no medidas o a una determinación imprecisa de los confusores. Por ejemplo, el nivel socioeconómico se asocia con varios resultados en salud y a menudo difiere entre los grupos que se comparan. Las variables que se utilizan para medir el nivel socioeconómico (ingresos, educación u ocupación) representan otras exposiciones no medidas y no definidas, y el verdadero confusor será medido, por definición, con error208. Los autores deben discutir el rango real de incertidumbre en los estimadores, el cual es mayor que la incertidumbre estadística reflejada en los intervalos de confianza. Esto último no toma en consideración otras incertidumbres que surgen del diseño, la implementación y los métodos de medida del estudio209.
Para guiar el juicio y las conclusiones respecto a la causalidad, algunos pueden encontrar útiles los criterios propuestos por Bradford Hill164 en 1965. ¿Cuán fuerte es la asociación con la exposición? ¿Precedió la exposición al inicio de la enfermedad? ¿La asociación es consistente con observaciones en diferentes estudios y contextos? ¿Hay evidencia que apoye los hallazgos provenientes de estudios experimentales, incluyendo estudios de laboratorio y en animales? ¿Cuán específica es la exposición para el efecto que se le imputa y existe una relación dosis-respuesta? ¿La asociación es biológicamente plausible? No obstante, estos criterios no se deben aplicar mecánicamente. Por ejemplo, algunos han argumentado que un riesgo relativo por debajo de 2 o 3 se debe ignorar210,211. Esto es contrario a lo expuesto por Cornfield et al127 acerca de la fuerza de los riesgos relativos grandes (ver punto 12b). Aunque un efecto causal es más probable con un riesgo relativo de 9, no se puede deducir que uno por debajo de 3 sea necesariamente falso. Por ejemplo, el pequeño incremento en el riesgo de presentar leucemia en la niñez después de haber recibido radiaciones intraútero es verosímil porque tiene que ver con un efecto adverso de un procedimiento médico, para el cual ninguna explicación alternativa es obvia212. Además, los efectos cancerígenos de la radiación están bien establecidos. El doble del riesgo de cáncer de ovario asociado a comer 2 o 4 huevos por semana no es creíble inmediatamente, puesto que los hábitos alimentarios se asocian con un gran número de factores del estilo de vida, así como con el nivel socioeconómico213. En contraste, la credibilidad de los ampliamente debatidos hallazgos epidemiológicos respecto a las diferencias en el riesgo de trombosis entre los distintos tipos de anticonceptivos orales aumentó enormemente por las diferencias en la coagulación que se encontraron en un estudio clínico cruzado y aleatorizado214. Siempre se debe incluir una discusión de la evidencia externa de diferentes tipos de estudios, pero esto puede ser particularmente importante para aquellos que comuniquen pequeños incrementos en el riesgo. Además, los autores deben contextualizar sus resultados con estudios similares y explicar cómo el nuevo estudio afecta el cuerpo de evidencia existente, idealmente refiriéndose a una revisión sistemática.
21. Generabilidad: discuta la posibilidad de generalizar los resultados (validez externa)Ejemplo“¿Son aplicables nuestras estimaciones a otros pacientes infectados por el VIH-1? Ésta es una pregunta importante, porque la precisión de los modelos pronóstico tiende a ser menor cuando se aplican datos distintos a los utilizados para el modelo. Nosotros tratamos este problema simplificando la complejidad de los modelos y escogiendo aquellos que mejor se generalizaran para las cohortes omitidas en el procedimiento de estimación. Nuestra base de datos incluyó pacientes de muchos países de Europa y Norteamérica que fueron tratados en diferentes contextos. La diversidad de pacientes fue amplia: se incluyeron hombres y mujeres, desde adolescentes hasta personas de edad avanzada, y las principales categorías de exposición estuvieron bien representadas. La gravedad de la inmunodeficiencia basal varió desde no medible hasta muy grave, y la carga viral desde indetectable hasta extremadamente alta”215.
ExplicaciónLa generabilidad, también llamada validez externa o aplicabilidad, se refiere al grado en que los resultados de un estudio se pueden aplicar a otras circunstancias216. No hay validez externa per se; el término sólo es significativo con respecto a condiciones específicas muy claras217. ¿Se pueden aplicar los resultados a individuos, grupos o poblaciones que difieren de aquellos que participaron en el estudio en lo que se refiere a edad, sexo, etnia, gravedad de la enfermedad y condiciones de comorbilidad? ¿La naturaleza y el grado de las exposiciones son comparables, y la definición de los eventos de interés es relevante para otros contextos o poblaciones? ¿Los datos recogidos en estudios longitudinales varios años atrás siguen siendo relevantes hoy día? ¿Los resultados de las investigaciones sobre servicios de salud en un país son aplicables a los sistemas de salud de otros países?
Con frecuencia, la pregunta sobre si los resultados de un estudio tienen validez externa es una cuestión de juicio que depende del contexto del estudio, de las características de los participantes, de las exposiciones estudiadas y de los desenlaces evaluados. Por lo tanto, es crucial que los autores presenten a los lectores información adecuada respecto a las condiciones y el lugar del estudio, los criterios de elegibilidad, las exposiciones y cómo se midieron, la definición del desenlace evaluado, así como el periodo de reclutamiento y de seguimiento. También son relevantes el grado de no participación y la proporción de participantes no expuestos en que se desarrolló el resultado. El conocimiento del riesgo absoluto y de la prevalencia de la exposición, que a menudo varían en las diferentes poblaciones, son de ayuda cuando se aplican resultados a otros ámbitos o poblaciones (véase el Recuadro 7).
Otra información22. Financiación: especifique la financiación y el papel de los patrocinadores del estudio, y si procede, del estudio previo en que se basa su artículoExplicaciónAlgunas publicaciones solicitan a los autores que declaren la presencia o ausencia de financiación y otros conflictos de intereses 100,218. Varias investigaciones muestran fuertes asociaciones entre el origen de la financiación y las conclusiones de los artículos de investigación219–222. Las conclusiones de algunos estudios clínicos aleatorizados han recomendado el fármaco en estudio como de elección con mucha más frecuencia (odds ratio de 5,3) si el estudio estaba financiado por organizaciones lucrativas, aun después de ajustar por el tamaño del efecto223. Otros estudios documentan la influencia de las industrias del tabaco y de telecomunicaciones en las investigaciones que éstas financian224–227. También hay ejemplos de influencia indebida cuando el patrocinador es el gobierno u organizaciones no lucrativas.
Los autores o patrocinadores pueden tener conflictos de intereses que influyan en cualquiera de los siguientes aspectos: el diseño del estudio228, la selección de las exposiciones228,229, los desenlaces230, los métodos estadísticos231 y la publicación selectiva de los resultados230 y de los estudios232. En consecuencia, el papel de los patrocinadores se debe describir con detalle: en qué parte del estudio tienen responsabilidad directa (por ejemplo, el diseño, la recogida de los datos, los análisis, el borrador del manuscrito, la decisión de publicar)100. Otras fuentes de influencia indebida incluyen a los empleadores (por ejemplo, los administradores de la universidad en el caso de los investigadores académicos y de los supervisores del gobierno, especialmente los asignados por motivos políticos, para los investigadores gubernamentales), comités asesores, litigantes y grupos de interés especiales.
Comentarios finalesLa Declaración STROBE tiene como fin ofrecer recomendaciones que ayuden a la comunicación de estudios observaciones en epidemiologia. Un buen artículo revela las fortalezas y las debilidades de un estudio, y facilita las interpretaciones sensatas y la aplicación de sus resultados. La Declaración STROBE también puede ayudar en la planificación de los estudios observacionales, y guiar a los revisores y editores en la evaluación de los manuscritos.
Este artículo explicativo se escribió para comentar la importancia de un informe transparente y completo de los estudios observacionales, para explicar el fundamento que respalda los diferentes puntos incluidos en la lista y para dar ejemplos de artículos publicados que consideramos bien realizados. Esperamos que el material presentado ayude a los autores y editores a utilizar la Declaración STROBE.
Hacemos hincapié en que la Declaración STROBE y otras recomendaciones sobre la comunicación de investigaciones13,233,234 deben ser vistas como documentos que han de evolucionar, que requieren una evaluación, un refinamiento y, si es necesario, un cambio continuo235,236. Por ejemplo, la Declaración CONSORT237 para la publicación de estudios clínicos paralelos aleatorizados se desarrolló a mediados de los años 1990. Desde entonces, los miembros del grupo tienen reuniones regulares para examinar la necesidad de revisar las recomendaciones; en 2001 apareció una versión revisada233 y ya hay otra en desarrollo. Igualmente, los principios presentados en este artículo y en la lista de la Declaración STROBE están abiertos a modificaciones en cuanto se acumulen nuevas evidencias y comentarios críticos. El sitio web de STROBE (www.strobe-statement.org) proporciona un foro de discusión y sugerencias para mejorar la lista, este documento explicativo y la información relacionada con la buena comunicación de los estudios epidemiológicos.
Varias revistas ya solicitan en sus instrucciones para los autores que se siga la Declaración STROBE (véase http://www.strobe-statement.org/ para la lista actual). Invitamos a otras revistas a adoptar la Declaración STROBE y a que nos lo hagan saber a través del sitio web. Las revistas que publicaron las recomendaciones STROBE dan acceso libre. Por lo tanto, la Declaración STROBE es ampliamente accesible para la comunidad biomédica.
Estamos agradecidos a Gerd Antes, Kay Dickersin, Shah Ebrahim y Richard Lilford por su apoyo a la Iniciativa STROBE. También queremos dar las gracias a las instituciones que han ofrecido sus instalaciones para las reuniones de trabajo del grupo de coordinación: Institute of Social and Preventive Medicine (ISPM), University of Bern, Bern, Suiza; Department of Social Medicine, University of Bristol, Bristol, Reino Unido; London School of Hygiene and Tropical Medicine, Londres, Reino Unido; Nordic Cochrane Centre, Copenhage, Dinamarca, y Centre for Statistics in Medicine, Oxford, Reino Unido. También queremos expresar nuestro agradecimiento a seis revisores que aportaron comentarios útiles a una versión previa de este artículo y al traductor y revisores de la traducción al español.
Finanaciación
El seminario en el que se estableció la Iniciativa STROBE fue financiado por la European Science Foundation (ESF). Se recibió también financiación del Medical Research Council Health Services Research Collaboration y del National Health Services Research and Development Methodology Programme.
Contribuciones de autoría
Todos los autores contribuyeron en la redacción del artículo. JPV, EvE, DGA, PCG, SJP y ME escribieron el primer borrador de diferentes secciones del artículo. EvE asume la mayor parte de las cuestiones prácticas relativas a la coordinación de STROBE. ME inició el grupo STROBE y, junto con EvE, organizó el primer seminario.
Miembros de la Iniciativa STROBE
Las siguientes personas han contribuido a los contenidos y la elaboración de la Declaración STROBE: Douglas G. Altman, Maria Blettner, Paolo Boffetta, Hermann Brenner, Geneviève Chêne, Cyrus Cooper, George Davey-Smith, Erik von Elm, Matthias Egger, France Gagnon, Peter C. Gøtzsche, Philip Greenland, Sander Greenland, Claire Infante-Rivard, John Ioannidis, Astrid James, Giselle Jones, Bruno Ledergerber, Julian Little, Margaret May, David Moher, Hooman Momen, Alfredo Morabia, Hal Morgenstern, Cynthia D. Mulrow, Fred Paccaud, Stuart J. Pocock, Charles Poole, Martin Röösli, Drummond Rennie, Dietrich Rothenbacher, Kenneth Rothman, Caroline Sabin, Willi Sauerbrei, Lale Say, James J. Schlesselman, Jonathan Sterne, Holly Syddall, Jan P. Vandenbroucke, Ian White, Susan Wieland, Hywel Williams y Guang Yong Zou.
Declaración de conflicto de intereses
Los autores declaran que no existen conflictos de interés.
Copyright: © 2007 Los Autores. Hay más detalles sobre el uso de este material en la página web STROBE (http://www.strobe-statement.org). Con el objetivo de fomentar la divulgación de la Declaración STROBE, este artículo también se ha publicado y está accesible gratuitamente en las revistas PLoS Medicine, Epidemiology y Annals of Internal Medicine.
La versión en español ha sido traducida del artículo publicado en PLoS Medicine (PLoS Med 4(10): e297) y ha sido autorizada y aprobada por el grupo coordinador de la Iniciativa STROBE. El responsable de la traducción es Mario E. Rojas-Russell y han colaborado Ma de los Ángeles Aedo-Santos, Hernán Chivardi-Olmos, Elsy A. García-Villegas, Eloísa Colín-Ramírez, Reyna L. Pacheco-Domínguez, Manuel C. Ortega-Álvarez, todos ellos de la Facultad de Medicina de la Universidad Nacional Autónoma de México. Los traductores agradecen a Miguel Klunder-Klunder y Clara Bellamy-Ortiz sus comentarios al texto. La traducción ha sido supervisada por Malaquías López-Cervantes, Carmen Company y Esteve Fernández.











