







Analizar cuáles deben ser los criterios clínicos y sociales en función de los cuales deben ser priorizados los pacientes en listas de espera quirúrgicas programadas.
MétodosSe estima un modelo de elección discreta (MED) utilizando una muestra representativa de la población general de Navarra. La muestra fue seleccionada mediante muestreo aleatorio simple por cuotas de edad y sexo, estratificada por areas y municipios de residencia de la población mayor de 18 años. La información obtenida se analizó por métodos bayesianos.
ResultadosLos pesos relativos de los atributos revelan que los problemas de salud del paciente, el coste de la intervención y el tiempo de espera son los 3 más importantes a la hora de priorizar a los pacientes. Conforme a lo esperado, la gravedad de la enfermedad se presenta como el atributo considerado de mayor importancia, y llama la atención la menor importancia de la mejora de la salud causada por la intervención. Estos resultados indican que la priorización de pacientes de acuerdo solamente al tiempo de espera no tendría en cuenta los aspectos considerados importantes por la población.
ConclusionesEl tiempo de espera no debería ser la única variable utilizada para la priorización de pacientes en las listas de espera. Un resultado interesante que deberá ser analizado en el futuro es la importancia otorgada al coste de la intervención. Este trabajo es otro ejemplo del potencial de los MED en economía de la salud, que teniendo en cuenta sus posibles limitaciones, puede ser útil para crear mecanismos de priorización de pacientes en las listas de espera.
To identify which clinical and social characteristics should be used to prioritize patients on the waiting list for elective surgical procedures.
MethodsA discrete choice experiment (DCE) was conducted using a representative sample of the general population in Navarre (Spain). The sample was selected through simple random sampling by age and sex quotas, stratified by the areas and municipalities of residence of the population aged more than 18 years old. Data were analyzed using Bayesian methods.
ResultsThe relative weights of attributes show that the most important attributes when prioritizing patients were the disease, the cost of the intervention, and waiting time. As expected, severity of illness was the most important attribute and, contrary to prior expectations, improvements in health were considered less important. These findings show that prioritization according to waiting time alone may not take into account other issues considered important by the general public.
ConclusionsPatients should not be prioritized according to waiting time only. An interesting finding that should be analyzed in future is that cost was considered an important prioritization criterion. This study provides a further example of the potential of DCE in health economics. If its limitations are borne in mind, this tool may be useful to develop prioritization scoring systems for patients on waiting lists.
Las listas de espera se utilizan como el principal instrumento de gestión de la demanda de intervenciones quirúrgicas. En ese sentido, casi un 80% de las intervenciones se realizan en pacientes que se encuentran en lista de espera1.
En general, las listas de espera se caracterizan por la diversa gravedad, tanto sintomática como funcional, de los pacientes y por la falta de relación entre dichas variables y el tiempo de espera. Esto precisa la utilización de algún sistema de priorización de los pacientes según el beneficio esperado de la intervención, y no solamente en función del tiempo de espera en lista o su gravedad. Normalmente, los criterios de priorización de pacientes los establecen los profesionales sanitarios. Sin embargo, en los sistemas sanitarios financiados públicamente, y desde un punto de vista económico, es importante considerar también los valores y las preferencias de todos los agentes implicados y afectados por el proceso de establecimiento de prioridades en las listas de espera.
El objetivo principal de este trabajo es establecer un sistema de priorización de pacientes en listas de espera quirúrgicas programadas, en función de un conjunto de criterios tanto clínicos como sociales. Algunos trabajos recientes han acometido también este objetivo, tanto desde un punto de vista general2 como de problemas de salud específicos3,4.
MétodosSe utiliza la metodología de los modelos de elección discreta (MED)5-7 aplicando métodos bayesianos y de estimación Gibbs sampling. Los MED se basan en la teoría del consumidor de Lancaster8 y en la utilidad aleatoria popularizada por McFadden9. Los MED asumen que la valoración que los sujetos hacen de un determinado bien o servicio (p. ej., su utilidad) depende de los niveles de los atributos que los caracterizan. Este trabajo se distingue de otros en los que se ha utilizado este tipo de técnicas en tres aspectos. En primer lugar, se incluye un atributo de coste. En segundo lugar, se aplica en un marco de listas quirúrgicas programadas genéricas, cuyos resultados podrían extrapolarse a diferentes tipos de intervenciones. En tercer lugar, se utiliza una muestra representativa de la población general, más apropiada en un sistema de financiación pública como el español.
Para llevar a cabo los objetivos propuestos en el trabajo, se estimó un modelo de elección discreta desarrollado en 5 etapas: identificación de los atributos; asignación de niveles a los atributos; diseño de los escenarios que serán presentados a los individuos (diferentes combinaciones de atributos y niveles); obtención de las preferencias para los escenarios y análisis de la información recogida.
Etapa 1. Identificación de los atributosA partir de una revisión de la literatura médica se obtuvo una lista de 12 posibles atributos. Para seleccionar los 5 que serían incluidos en el trabajo se realizó una encuesta a un grupo de 22 personas, pertenecientes a los Departamentos de Economía y Gestión de Empresas de la Universidad Pública de Navarra. En dicho cuestionario se pedía a los encuestados que seleccionaran 5 atributos y los enumeraran por orden de importancia de una lista de 12. El equipo de investigación decidió combinar varios de los atributos en uno más general, «problemas en el estado de salud» actual del paciente antes de la intervención. Se decidió también introducir un atributo de coste. Esto no es raro en la aplicación de los MED, pues nos da una medida de la disponibilidad de pagar por cambios marginales en los atributos y, además, en este caso concreto, nos revela en qué medida los individuos estarían dispuestos a priorizar pacientes en función del coste de su intervención, lo cual es también un criterio importante en la política sanitaria. Los atributos finalmente seleccionados se presentan en la tabla 1.
Atributos incluidos en el estudio
| Lista previa de atributos | Atributos seleccionados |
| Estado de salud general antes de la operación | 1. «Problema en el estado de salud» actual del paciente antes de la intervención |
| Estado de progresión de la enfermedad | 2. «Mejora de la salud» que el paciente puede obtener debido a la intervención |
| Problemas de movilidad causados por la enfermedad | 3. «Coste» que soporta el Servicio de Salud por la intervención |
| Depende de otras personas para realizar actividades cotidianas | 4. «Edad en años» del paciente |
| Problemas de dolor/malestar causados por la enfermedad | 5. «Tiempo de espera» en una lista para ser intervenido |
| Problemas de ansiedad/depresión | |
| «Mejora de la salud» que el paciente puede obtener debido a la intervención | |
| Edad en años del paciente | |
| Tiempo de espera en la lista para ser intervenido | |
| Nivel de renta del paciente | |
| Hábitos de vida perjudiciales (tabaquismo, alcoholismo…) | |
| Pérdida de ocupación causada por la enfermedad |
Se establecieron 4 niveles para cada atributo, tratando de que éstos fueran realistas. Para ello, se revisó la información referente a los tiempos de espera del Servicio Navarro de Salud-Osasunbidea y del Servicio Riojano de Salud. En la tabla 2 se muestran los niveles asignados a cada atributo.
Etapa 3. Construcción de los pares de elecciónPara crear las elecciones incluidas en el cuestionario se empleó un diseño fraccional factorial, que cumplía las propiedades de ortogonalidad, balanceado (level balance) y mínimum overlap. De las 1.024 combinaciones diferentes a las que dan lugar los 5 atributos y 4 niveles, se definieron 16 pares de pacientes hipotéticos.
Etapa 4. Obtención de las preferencias para los 16 escenariosUna vez definidos los pares de elecciones, éstos se incluyeron en el cuestionario suministrado a la muestra seleccionada. En esta ocasión, a cada encuestado se le presentaron 16 pares de hipotéticos pacientes y se les pidió que eligieran cuál incluirían antes en una lista de espera, mediante el siguiente texto: «Señale el paciente que debería ser operado en primer lugar». Cada elección fue presentada a los encuestados en tarjetas individuales. Con el fin de facilitar la comprensión por parte de los encuestados, el encuestador realizaba un ejemplo con 2 pacientes hipotéticos, y aclaraba las dudas, en caso de que hubiera, antes de iniciar la encuesta. Ninguno de los encuestados manifestó problemas de comprensión. En el anexo 1 se presenta la información que fue facilitada a los entrevistados sobre los atributos y sus respectivos niveles. En la tabla 3 se presenta un ejemplo de una de las elecciones utilizada en la encuesta.
Su opinión sobre la organización de las listas de espera quirúrgicas
| En esta sección nos gustaría conocer su opinión sobre cómo deberían ser priorizados (ordenados) los pacientes en las listas de espera para intervenciones quirúrgicas programadas |
| Los pacientes que esperan se diferencian en función de las características, es decir, motivos o circunstancias por los cuales podrían ser adelantados o retrasados en la lista de espera |
|
| Cada una de estas características tiene distintos niveles, descritos a continuación: |
|
|
|
|
|
| Sección 1 |
| Considere ahora las siguientes preguntas. En cada una de ellas, le presentamos 2 pacientes hipotéticos y nos gustaría que en cada una eligiese qué paciente colocaría usted por delante en la lista de espera |
| Se supone que en cada pregunta los pacientes hipotéticos son distintos |
| Por favor, conteste a todas las preguntas |
| No hay respuestas correctas o falsas. Sólo nos interesa su opinión |
| Elección 1. Señale el paciente que debería ser operado en primer lugar (entregar tarjetas) |
Ejemplo de una elección discreta utilizada en la encuesta
| Elección 16. Señale el paciente que debería ser operado en primer lugar | ||
| Paciente F | Paciente G | |
| Problema de salud | Leve | Muy grave |
| Mejora de la salud | Moderada | Completa |
| Coste (€) | 1.000 | 2.000 |
| Edad (años) | 80 | 65 |
| Tiempo de espera (meses) | 8 | 2 |
| Orden | 1 | 2 |
Los 16 pares de elecciones se incluyeron en un cuestionario que constaba de dos partes. La primera parte incluía cuestiones relacionadas con la satisfacción de la población con el sistema sanitario público navarro10, y la segunda consistía en el experimento de elección discreta. Antes de que se presentaran las elecciones a los encuestados, se proporcionó información sobre los atributos y los niveles. Se solicitó también a los encuestados que enumerasen los atributos por orden de importancia. Finalmente, se recogió información de carácter sociodemográfico.
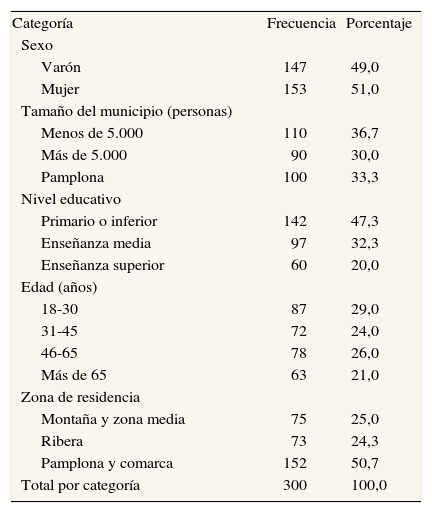
Para llevar a cabo el estudio, se seleccionó una muestra aleatoria simple por cuotas de edad y sexo de 300 personas, estratificada por áreas y municipios de residencia de la población mayor de 18 años y representativa de la población general de Navarra (600.000 habitantes). En la tabla 4 se describen las principales características de la muestra.
Descripción de la muestra
| Categoría | Frecuencia | Porcentaje |
| Sexo | ||
| Varón | 147 | 49,0 |
| Mujer | 153 | 51,0 |
| Tamaño del municipio (personas) | ||
| Menos de 5.000 | 110 | 36,7 |
| Más de 5.000 | 90 | 30,0 |
| Pamplona | 100 | 33,3 |
| Nivel educativo | ||
| Primario o inferior | 142 | 47,3 |
| Enseñanza media | 97 | 32,3 |
| Enseñanza superior | 60 | 20,0 |
| Edad (años) | ||
| 18-30 | 87 | 29,0 |
| 31-45 | 72 | 24,0 |
| 46-65 | 78 | 26,0 |
| Más de 65 | 63 | 21,0 |
| Zona de residencia | ||
| Montaña y zona media | 75 | 25,0 |
| Ribera | 73 | 24,3 |
| Pamplona y comarca | 152 | 50,7 |
| Total por categoría | 300 | 100,0 |
La encuesta se realizó mediante entrevistas personales en el domicilio de los encuestados, con el fin explicar mejor el ejercicio y garantizar una mayor validez de los resultados. Además, se establecieron de forma aleatoria dos suplentes por encuestado, de manera que si una persona no pudiera ser localizada era sustituida por otra de iguales características en cuanto a edad, sexo y área de residencia, con lo que se obtuvo un total de 300 respuestas.
Etapa 5. Análisis de datosUna vez obtenidas las respuestas, éstas se analizaron mediante métodos econométricos. Para ello, se utilizaron métodos bayesianos, usando el método de estimación Gibbs sampling mediante el programa estadístico WinBUGS en su versión 1.411. Se estimó la siguiente función de utilidad a través del modelo de elección binaria:
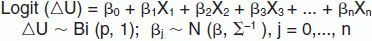
Donde U es el cambio en utilidad de pasar de la elección 1 a 2, Xj (j = 1, 2,…, n) son las diferencias en los niveles de los atributos entre 1 y 2, y βj (j = 0, 1,…, n) son los coeficientes del modelo a estimar, los cuales siguen una distribución Normal.
La estadística bayesiana permite, a partir de las distribuciones a posteriori de los coeficientes, la realización de estimaciones puntuales y el cálculo de intervalos de credibilidad (IC). Se utilizaron distribuciones no informativas como una primera aproximación al problema. Cuando en el modelo se carece de conocimiento inicial a través de distribuciones a priori no informativas, esta no información viene recogida por los siguientes parámetros:
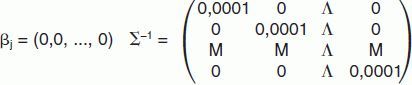
Se realizaron un total de 100.000 iteraciones (después de un burn-in de 10.000). Los datos usados en el modelo logit fueron 9.600 (300 individuos × [16 elecciones × 2 opciones 1 y 2] = 9.600). A fin de evitar la multicolinealidad se establecieron distintos niveles de referencia para cada uno de los atributos. Estos niveles fueron, respectivamente: muy leve, ligera, 1.000 euros, 16 años y 2 meses.
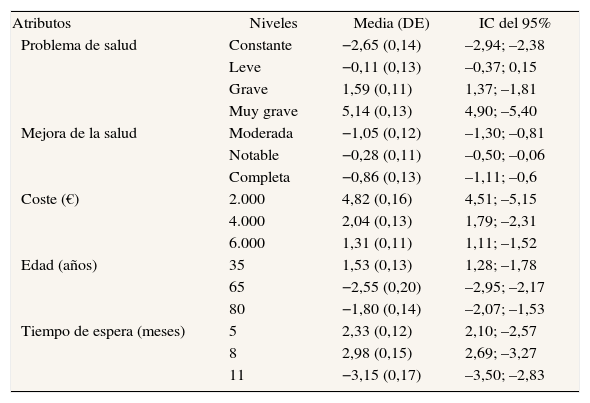
ResultadosEn la tabla 5 se muestran las distribuciones a posteriori de los coeficientes en el modelo logit. La inclusión del valor cero en el IC bayesiano de un coeficiente implica que la probabilidad de conocer el sentido al que está afectando la variable asociada a ese coeficiente es menor del 95%. En este caso sólo el nivel «leve» en el atributo «problemas de salud» presenta el valor cero dentro del intervalo. Por otro lado, a la luz de los resultados obtenidos observamos que un problema de salud «muy leve» se valora 5,14 menos que un problema de salud «muy grave», y 1,59 menos que un problema de salud «grave». De esto se podría concluir que los niveles del atributo «problemas de salud» mantienen una relación positiva, en el sentido de que a mayor gravedad en el problema de salud la valoración de que el paciente debe ser operado en primer lugar es mayor. Cabe resaltar que éste es el único atributo con esta característica.
Resultados del modelo de regresión logit. Distribución a posteriori de los coeficientes de interés
| Atributos | Niveles | Media (DE) | IC del 95% |
| Problema de salud | Constante | −2,65 (0,14) | –2,94; –2,38 |
| Leve | −0,11 (0,13) | –0,37; 0,15 | |
| Grave | 1,59 (0,11) | 1,37; –1,81 | |
| Muy grave | 5,14 (0,13) | 4,90; –5,40 | |
| Mejora de la salud | Moderada | −1,05 (0,12) | –1,30; –0,81 |
| Notable | −0,28 (0,11) | –0,50; –0,06 | |
| Completa | −0,86 (0,13) | –1,11; –0,6 | |
| Coste (€) | 2.000 | 4,82 (0,16) | 4,51; –5,15 |
| 4.000 | 2,04 (0,13) | 1,79; –2,31 | |
| 6.000 | 1,31 (0,11) | 1,11; –1,52 | |
| Edad (años) | 35 | 1,53 (0,13) | 1,28; –1,78 |
| 65 | −2,55 (0,20) | –2,95; –2,17 | |
| 80 | −1,80 (0,14) | –2,07; –1,53 | |
| Tiempo de espera (meses) | 5 | 2,33 (0,12) | 2,10; –2,57 |
| 8 | 2,98 (0,15) | 2,69; –3,27 | |
| 11 | −3,15 (0,17) | –3,50; –2,83 |
DE: desviación estándar; IC: intervalo de credibilidad.
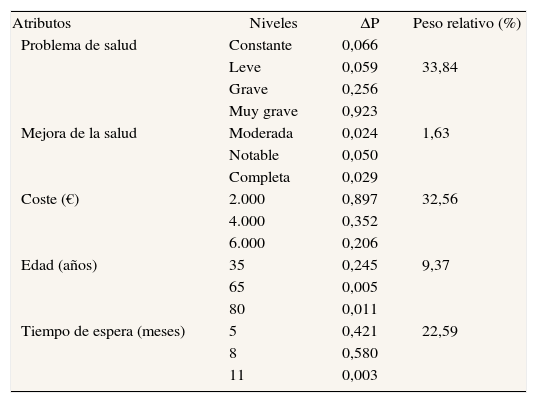
A continuación, se analiza la importancia relativa de los 5 atributos (tabla 6). Ésta depende del rango de variación de los niveles de cada atributo. Para ello, se calcula en primer lugar la variable dependiente explicada en el modelo logit para cada uno de los niveles (ΔP), lo que representa la variación en la probabilidad de que un paciente sea priorizado en la lista de espera ante un incremento unitario en uno de los niveles, manteniendo el resto en el nivel de referencia. La probabilidad de ser priorizado en los niveles de referencia es 0,066. Posteriormente, se obtiene el peso relativo de los distintos atributos como el cociente entre el rango de variación del atributo y entre la suma de los rangos de variación de todos los niveles. El rango de variación es la diferencia entre el valor máximo y el mínimo de ΔP entre los distintos niveles, teniendo en cuenta que el nivel de referencia es igual a 0,066 y puede influir en el rango de variación.
Variaciones en las medidas de probabilidad (AP) de los distintos niveles de que un paciente sea priorizado y pesos relativos de los atributos
| Atributos | Niveles | ΔP | Peso relativo (%) |
| Problema de salud | Constante | 0,066 | |
| Leve | 0,059 | 33,84 | |
| Grave | 0,256 | ||
| Muy grave | 0,923 | ||
| Mejora de la salud | Moderada | 0,024 | 1,63 |
| Notable | 0,050 | ||
| Completa | 0,029 | ||
| Coste (€) | 2.000 | 0,897 | 32,56 |
| 4.000 | 0,352 | ||
| 6.000 | 0,206 | ||
| Edad (años) | 35 | 0,245 | 9,37 |
| 65 | 0,005 | ||
| 80 | 0,011 | ||
| Tiempo de espera (meses) | 5 | 0,421 | 22,59 |
| 8 | 0,580 | ||
| 11 | 0,003 |
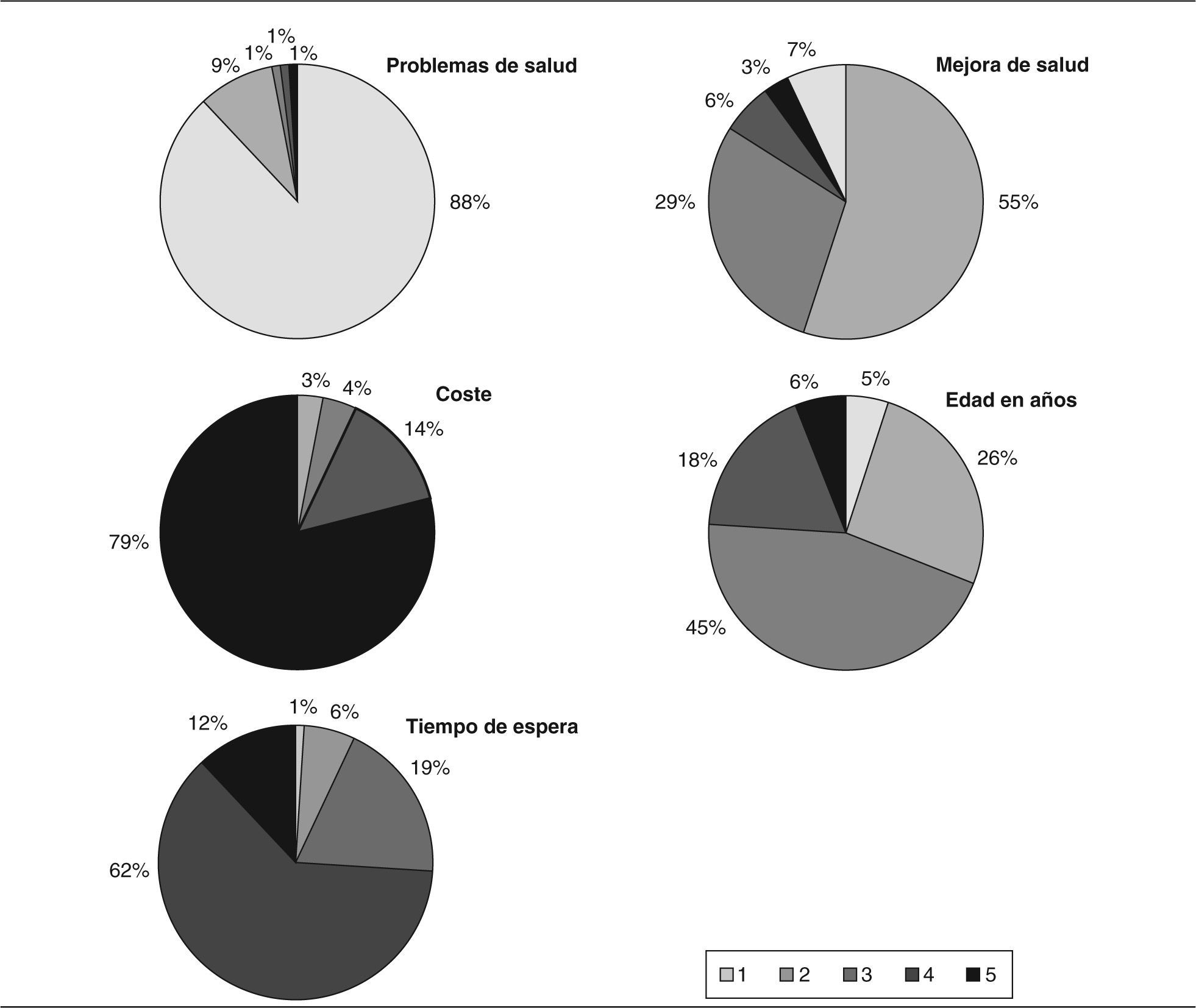
El atributo que recibe un mayor peso relativo es el de problema de salud que, a su vez, es el que mayor importancia tiene para los encuestados (fig. 1). El segundo y tercer atributos con mayores pesos relativos son el coste y el tiempo de espera. El atributo mejora en salud es el que menor peso relativo tiene de todos los atributos con diferencia (1,63%), es decir, es el que menos está influyendo a la hora de priorizar a un paciente. En cuanto a los niveles, más de 11 meses es el que menor variación en probabilidad tiene de todos los atributos (0,003), es decir, el que está afectando menos en la probabilidad de que un paciente sea priorizado.

Estos resultados contrastan con la importancia que atribuyen los encuestados a cada uno de esos atributos por separado. Como se aprecia en la figura 1, los problemas de salud se consideran el criterio más importante, seguido de la mejora de salud. El coste en cambio se considera como menos importante por el 79% de la muestra, seguido del tiempo de espera. Sin embargo, como se discute a continuación, esto no debería considerarse como un signo de algún tipo de inconsistencia en las respuestas obtenidas.
DiscusiónEl objetivo de este estudio era aplicar y utilizar una herramienta que nos permitiera ordenar a los pacientes en una lista de espera en función de un conjunto amplio de criterios y no sólo el tiempo que llevan esperando en lista o su estado de salud. Para ello, se han utilizado los MED según la hipótesis de que la priorización de los pacientes en lista de espera puede basarse en 5 atributos: el problema de salud del paciente, su mejora potencial tras la intervención, el coste de la intervención, la edad y el tiempo que lleva en lista de espera.
Varias cuestiones deben tenerse en cuenta al interpretar los resultados obtenidos. En primer lugar, las estimaciones del modelo indican que en términos relativos, la gravedad del problema de salud, el coste del tratamiento y el tiempo de espera son los 3 criterios de priorización más importantes. De forma contraria a lo esperado, la mejora de salud esperada tiene el menor peso relativo de los 5 atributos. Esto puede deberse a la importancia que los encuestados han otorgado al atributo «problema de salud». Su elevado peso relativo (33,84%) nos revela que las personas tratarían primero a los pacientes con peor estado de salud, a los más graves. Esto nos puede estar indicando dos cuestiones importantes. Por una parte, los individuos no piensan ni deciden en términos de «ganancia esperada de salud» (como nos diría la teoría de los años de vida ajustados en función de la calidad), sino en términos de «estado de salud actual». Posiblemente, los encuestados suponen que el mero hecho de tratar o intervenir a una persona cuyo estado de salud es muy grave y que está en lista de espera ya supondrá una mejora de su estado de su salud y, en ese sentido, se prefiere tratar a los pacientes que están muy graves porque asumen que la intervención mejorará su estado de salud, lo cual podría explicar el bajo peso que se da al atributo «mejora de la salud».
Por otro lado, puede estar reflejando una fuerte preferencia (¿lexicográfica?) por el atributo «problema de salud», de tal manera que los individuos siempre priorizarían al paciente con peor estado de salud y, siendo éste igual para 2 pacientes, considerarían otros atributos. Esto puede reflejarse por el hecho de que, como se muestra en la tabla 6, ante un cambio en este nivel, la probabilidad de que el paciente sea priorizado es la mayor de todas. Si esto fuese así, implicaría que se prefiere tratar antes a una persona con un problema de salud muy grave y con una mejora de salud moderada, que a una persona con un problema de salud grave (o leve) pero con una mejora de salud completa. El trabajo no fue diseñado para intentar testar la existencia de este tipo de preferencias, por otra parte de muy difícil comprobación en estudios de este tipo. Estas cuestiones nos advierten sobre la importancia y la necesidad de tener en cuenta y conocer con mayor profundidad (quizá con métodos cualitativos) las preferencias y los procesos de decisión de los encuestados, con el fin de entender mejor sus respuestas y elecciones.
Un segundo resultado que merece comentario es el elevado peso relativo del atributo coste, y quizá más aún la forma de «U invertida» de esta variable en relación con la variable dependiente. Sin embargo, el hecho de que la probabilidad de priorizar pacientes aumente al pasar de 6.000 a 4.000 y de 4.000 a 2.000 euros no sería del todo sorprendente. De hecho, este resultado nos podría estar indicando que el coste es importante para los encuestados, en el sentido de que, dado que dicho coste afectaría a su bolsillo (como se menciona en su descripción), los individuos priorizarían los menos costosos. El resultado no esperado es el valor del parámetro del «nivel 1.000», que dificulta su interpretación.
Contrasta también con el hecho de que los individuos conceden poca importancia al atributo de coste cuando éste se considera de forma directa. Sin embargo, hay que tener en cuenta que estas dos formas de preguntar son básicamente diferentes. Es decir, lo fundamental en los MED es precisamente que la valoración de los atributos es relativa. Como ejemplo, preguntados sobre el precio directamente, normalmente preferimos menor precio, pero si menor precio implica muy mala calidad, entonces nuestra disponibilidad para pagar cambia y estamos dispuestos a pagar un mayor precio por más calidad. Es decir, la distinta valoración de un atributo preguntado directamente respecto a cuando se incluye en un ejercicio de trade-off es algo incluso esperado.
El atributo «tiempo de espera» presenta también un comportamiento no monótono, lo cual también dificulta su interpretación. Sin embargo, es frecuente encontrar este tipo de resultados en la aplicación de MED, como en el caso de Rivera et al4, donde los atributos tiempo de espera y edad no presentan un comportamiento monótono. Pese a ello, hay una tendencia a favor de no eliminar las respuestas «irracionales» con el fin de buscar los resultados esperados12.
En este estudio, en el caso del atributo «tiempo de espera», el nivel que resulta «inusual» es el de más de 11 meses, que es el que menor variación en probabilidad tiene de todos los atributos (0,003), es decir, el que está afectando menos sobre la probabilidad de que un paciente sea priorizado. Lo mismo ocurre para el atributo «mejora de la salud», que es el que menor peso relativo (1,63%) y, por tanto, el que menos está influyendo a la hora de priorizar a un paciente.
Otro aspecto interesante es el diseño del estudio, que utiliza un enfoque general y no de un tratamiento concreto. Esto presenta alguna ventaja. En concreto, puede ser más difícil para los encuestados imaginar el estado de salud de un paciente hipotético con una dolencia o enfermedad concreta (p. ej., puede resultar difícil para una persona de 27 años imaginar cuál es el estado de salud de una persona de 56 años con dolores crónicos en una rodilla o el de un paciente con un problema de desgaste de cadera). Por otra parte, el hecho de «anclar» la descripción del estado de salud no evitaría necesariamente que los encuestados pudieran tratar de pensar en alguien cercano con un problema similar con el fin de facilitar o simplificar su decisión, dando lugar a posibles sesgos.
Por otra parte, un enfoque general no tiene en cuenta las características de cada proceso y de cada dolencia, lo cual va en contra de la idea de que la organización y la gestión de las listas de espera debe abordarse teniendo en cuenta su heterogeneidad, ya que la urgencia de atención en diferentes procesos no es la misma y, por tanto, la espera y los criterios por los cuales los pacientes son priorizados en la lista deberían variar.
En definitiva, los resultados aquí obtenidos deben ser considerados con cautela, y ya plantean cuestiones sobre las que será necesario seguir trabajando en el futuro. Sin embargo, se ha mostrado que los MED son una herramienta que puede ser útil también para la medición de preferencias en el caso de la priorización de pacientes en listas de espera.
AgradecimientosAgradecemos los valiosos comentarios de dos revisores anónimos, los cuales han servido para mejorar el trabajo.











