



La no respuesta es un problema creciente en encuestas poblacionales que puede ser causa de sesgo de no-respuesta cuando respondedores y no respondedores difieren sistemáticamente.
ObjetivoComparar los resultados obtenidos mediante dos técnicas de corrección para el sesgo de no-respuesta: sustitución muestral y pesos de no respuesta obtenidos mediante propensión a responder.
MétodosSe comparan los efectos de la sustitución muestral semicontrolada y el uso de pesos de ajuste obtenidos mediante la propensión a responder sobre seis resultados de una encuesta de salud.
ResultadosA pesar de las diferencias significativas entre respondedores y no respondedores, mediante la corrección las prevalencias estimadas sólo cambian levemente, dando ambas técnicas de ajuste resultados similares. Sólo en el caso del tabaquismo, la sustitución muestral parece haber aumentado el sesgo de la estimación.
ConclusionesNuestros resultados sugieren que tanto mediante un procedimiento de sustitución muestral semicontrolada, como a través del ajuste estadístico de la no respuesta mediante la propensión a responder, se obtienen estimaciones de prevalencias corregidas similares.
Unit non-response is a growing problem in sample surveys that can bias survey estimates if respondents and non-respondents differ systematically.
ObjetivesTo compare the results of two nonresponse adjustment methods: field substitution and weighting nonresponse adjustment based on response propensity.
MethodsField substitution and response propensity weights are used to adjust for non-response and their effect on the prevalence of six survey outcomes is compared.
ResultsAlthough significant differences are found between respondents and non-respondents, only slight changes on prevalence estimates are observed after adjustment, with both techniques showing similar results. In the sole case of smoking, substitution seems to have further biased survey estimates.
ConclusionsOur results suggest that when there is information available for both respondents and non-respondents, or if a careful sample substitution process is performed, weighting adjustments based on response propensity and field substitution produce comparable results on prevalence estimates.
La no respuesta en una encuesta se define como el fracaso en obtener la participación de todas las unidades muestrales seleccionadas1, y constituye un problema creciente en las encuestas poblacionales2,3,4,5. Debe distinguirse de la no respuesta a ciertos ítems del cuestionario, lo que se conoce como «valores faltantes»6. Las estimaciones poblacionales obtenidas a partir de la muestra de sujetos que responden a la encuesta pueden diferir de las estimaciones que se habrían obtenido si el total de la muestra hubiera respondido a la encuesta. Esta diferencia se conoce como «sesgo de no respuesta» y se produce si los sujetos que no responden difieren sistemáticamente de los que responden en aquellas características que son de interés para el estudio7,8.
Aunque no es posible evitar el sesgo de no respuesta, se puede atenuar con estrategias de corrección. Es frecuente hacerlo mediante la sustitución muestral, en la cual se reemplazan los no respondedores por sujetos seleccionados aleatoriamente del marco muestral o por sujetos de características similares a los no respondedores (sustitutos pareados9). Las principales ventajas de la sustitución muestral son la conservación del tamaño y la estructura de la muestra9,10, así como la posibilidad de enfocar la sustitución en grupos específicos con tasas elevadas de no respuesta para asegurar su representatividad en la muestra11. Las principales críticas que se le hacen son que aumenta los costes de las encuestas9 y que no elimina el sesgo de no respuesta, ya que selecciona respondedores, que serán más parecidos a los sujetos que ya existen en la muestra que a los no respondedores que se pretende reemplazar11. Esto produce un sesgo neto de sustitución, que se suma al sesgo de no respuesta12, y puede introducir más sesgo que otras técnicas11. Adicionalmente, es frecuente que en los estudios que emplean sustitutos se invierta menos esfuerzo en contactar con los sujetos de la muestra original, y en consecuencia se reduzca la tasa de respuesta9,11,12. Aunque es un método que se utiliza con frecuencia en las encuestas con muestras probabilísticas9,11, se encuentra escasa bibliografía de investigación sobre él.
Otra forma de corregir los resultados de una encuesta es mediante métodos estadísticos que asignan a los respondedores un factor de ajuste (factor de no respuesta)6,13,14,15 que les permite dar cuenta de los no respondedores. Estos métodos consisten en dividir la muestra original en estratos homogéneos, construidos con la información que esté disponible tanto para respondedores como para no respondedores (p. ej., sexo, edad), en los cuales se asume que las respuestas de los no respondedores hubieran sido similares a las de los respondedores14. El factor de ajuste se calcula como el inverso de la tasa de respuesta en cada estrato, y se asigna a todos los respondedores de ese estrato.
Cuanta más información (mayor número de variables) se tenga de respondedores y no respondedores, mayor será el número de estratos a crear y mayor la probabilidad de que en alguno de ellos haya muy pocos o ningún respondedor, con lo que este factor de ajuste se vuelve muy inestable16. Little13 propone utilizar una única variable de estratificación consistente en la «propensión a responder», basada en la teoría de Rosenbaun y Rubin del propensity score17. Éste se calcula utilizando toda la información disponible para respondedores y no respondedores. De este modo se puede corregir el sesgo de no respuesta ajustando los resultados por un gran número de variables. De acuerdo con la teoría de Rosenbaun y Rubin, y (el atributo en estudio, p. ej., la hipertensión arterial) sería independiente de ser o no ser respondedor, condicional en la «propensión a responder»13.
La primera Encuesta Nacional de Salud de Chile (ENS_2003) tuvo como objetivo medir la prevalencia de 21 problemas de salud en la población chilena adulta. Su marco muestral lo constituyó la Encuesta Nacional de Calidad de Vida realizada en el año 2000 (ECV_2000) que, al no haber sido diseñada como un panel, no estableció un sistema de seguimiento de los sujetos encuestados. En consecuencia, el equipo investigador de la ENS_2003 esperaba tener dificultades para reclutar a los participantes, por lo que diseñó una estrategia de sustitución de la pérdida muestral para conservar el tamaño y la idoneidad de la muestra.
Para la investigación se utilizó la base de datos de la ECV_2000, que contenía información sobre los respondedores y no respondedores de la ENS_2003, para estimar la propensión a responder y obtener un factor de ajuste para la no respuesta. En este artículo se comparan los resultados obtenidos mediante el ajuste basado en la propensión a responder y mediante la sustitución muestral, y se hacen algunas recomendaciones respecto a la inclusión de uno u otro método en el diseño de encuestas poblacionales.
Material y métodosLa Encuesta Nacional de Calidad de Vida (ECV_2000) fue realizada por el Instituto Nacional de Estadísticas (INE) en el año 2000 y tuvo cobertura nacional, regional y urbano-rural. El muestreo fue trietápico, por conglomerados, viviendas e individuos, y el cuestionario estaba compuesto por un módulo sociodemográfico, uno familiar y otro individual18.
La Encuesta Nacional de Salud (ENS_2003) la condujo la Pontificia Universidad Católica de Chile por encargo del Ministerio de Salud (Minsal), y fue aprobada por los comités de ética de ambas instituciones. Se administró a una muestra representativa de los mayores de 17 años del país, consistente en una submuestra de los 6.228 sujetos que respondieron al módulo individual de la ECV_2000 (n=3492). Para este submuestreo se crearon ocho estratos, según sexo y cuatro grupos de edad19, dentro de los cuales la selección de los sujetos fue sistemática y con igual probabilidad. El muestreo fue no proporcional, con sobremuestreo de adultos mayores y personas de zona rural para obtener precisión en las estimaciones en todos los grupos.
La encuesta se realizó a domicilio en dos visitas. En la primera, los participantes firmaron el consentimiento informado y se les aplicó la encuesta sobre síntomas clínicos y antecedentes médicos; en la segunda se realizaron una serie de mediciones (peso, talla, presión arterial, etc.) y se tomaron muestras biológicas (p. ej., sangre y orina)19.
La sustitución muestral fue semicontrolada en tanto que los potenciales reemplazantes se seleccionaron del mismo marco muestral (ECV_2000), pareados por sexo, tramo de edad y segmento geográfico. En aquellos casos en que no existía un sustituto adecuado se tomaron de la población circundante, seleccionando una persona del mismo sexo y edad mediante tabla Kish20.
La no respuesta se registró en hojas de ruta y fue codificada para cada visita al domicilio. En este estudio la respuesta se analizó dicotómicamente (responde, no responde) en relación a la primera visita.
El tamaño muestral en la ENS_2003 fue de 3.616 personas, es decir, 188 sujetos más que el tamaño muestral utilizado para el ajuste estadístico de la no respuesta. Esta diferencia se debe a que la ENS_2003 sustituyó sobre el terreno a las personas que quedaron excluidas por diseño de acuerdo con los criterios de inclusión y exclusión fijados (no elegibles, n=64), y a que la ENS_2003 amplió la muestra de la VIII región en 124 personas que no participaron en la ECV_2000. Del total de sustitutos, 385 fueron seleccionados a priori del marco muestral y 1.494 (79,5%) se seleccionaron sobre el terreno.
Análisis estadísticoDescriptivoSe calculó la tasa de respuesta de la muestra original, eliminando del denominador los sujetos no elegibles. Se realizó un análisis de las diferencias entre respondedores y no respondedores utilizando la distribución porcentual de algunas características seleccionadas y el χ2 de Pearson para las comparaciones estadísticas.
Corrección de prevalencias mediante «propensión a responder» (ajuste estadístico)El procedimiento para obtener el factor de ajuste se basó principalmente en tres artículos: Little (1986)13, Little y Vartivarian (2003)21, y Vartivarian y Little (2002)16. Se estimó la propensión a responder de cada sujeto elegible de la muestra mediante una regresión logística13,14 tipo enter, con variable resultado responde/no responde. Se utilizaron como variables independientes las variables de muestreo (sexo, edad, comuna, región, zona urbano-rural) y variables provenientes de los tres módulos de la ECV_2000. Para el cálculo no se utilizaron los pesos muestrales21. A los sujetos con valores faltantes en alguna variable independiente se les ajustó un modelo con menos variables. Los sujetos no elegibles fueron eliminados de la muestra.
A continuación se dividió la muestra en quintiles (estratos) según la propensión a responder estimada. Dentro de cada estrato se asignó a los respondedores el «factor de ajuste por no respuesta», calculado como el inverso de la tasa de respuesta en ese estrato6,13,14,15,21,22.
Para evaluar la capacidad de corrección del factor de ajuste por no respuesta, se comparó la distribución por edad, sexo y nivel socioeconómico de la muestra original con los respondedores antes y después de realizar la corrección. Adicionalmente, dado que un proceso de ajuste estadístico podría aumentar en algunos casos el sesgo de las estimaciones23, se evaluó el modelo especificado de propensión a responder. Se regresó Y (presencia de la enfermedad de interés) en la muestra de respondedores, por su propensión estimada a responder. Se interpreta que cuando el coeficiente de esta regresión es significativamente distinto de cero, la propensión a responder es predictiva de la presencia de enfermedad y está indicado utilizar el modelo para obtener el factor de ajuste13.
Pesos muestralesPara calcular las prevalencias poblacionales, con y sin corregir, se restituyó a cada encuestado el peso que representa en el país, proceso conocido como expansión de la muestra19, actualizándolo a la población de agosto de 200318. En el caso de la sustitución, los pesos del sujeto originalmente seleccionado se trasladaron al reemplazante. Para el ajuste estadístico se utilizó el producto entre los pesos muestrales y el factor de ajuste por no respuesta.
Los valores faltantes para cada problema de salud se dejaron como valores missing. Todos los análisis estadísticos se realizaron utilizando el paquete estadístico SPSS versión 13.0 para Windows.
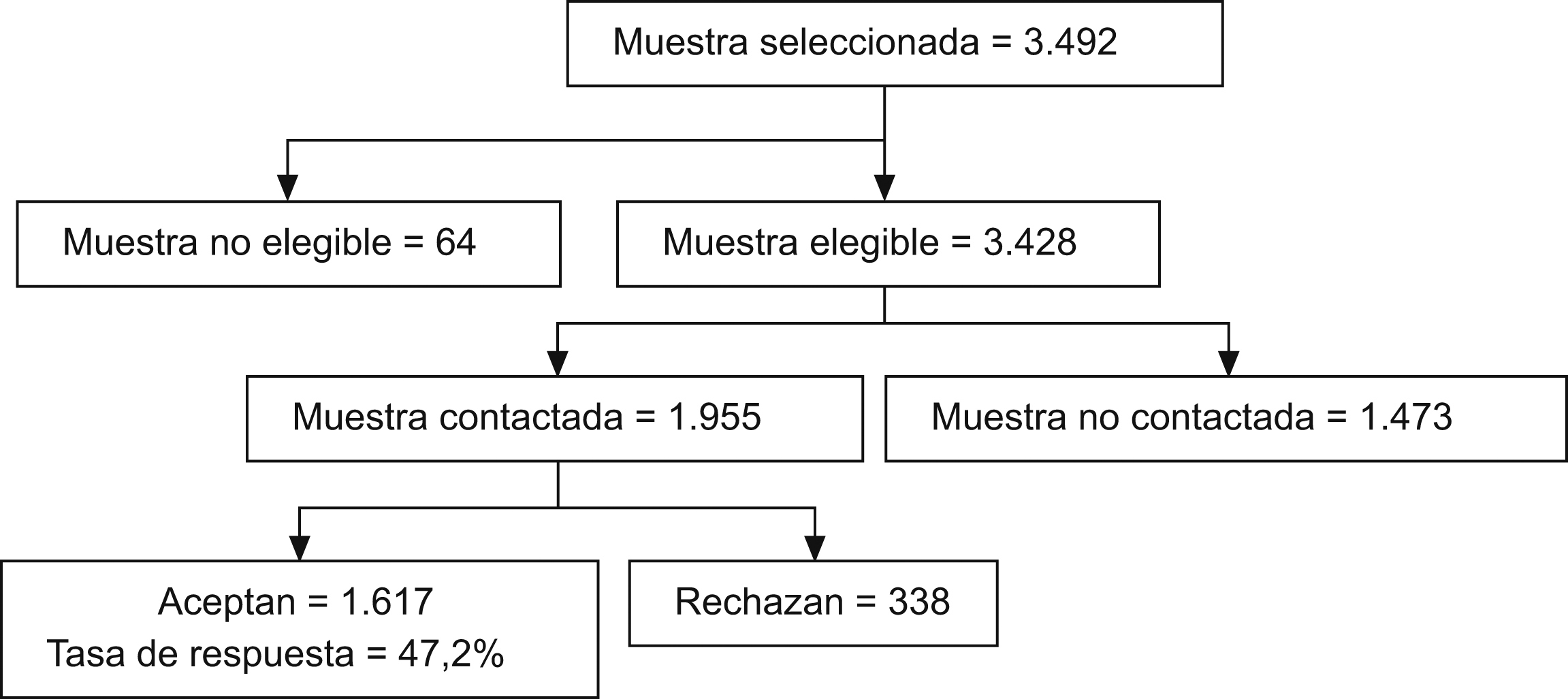
ResultadosLa tasa de respuesta entre los 3.482 sujetos elegibles de la muestra original fue del 47,2%. Hubo 1.473 personas a las que no se pudo establecer contacto y 338 personas que rechazaron responder a la encuesta, lo cual supone una tasa de no respuesta del 52,8%. Sesenta y cuatro sujetos resultaron no elegibles (50 fallecidos y 14 excluidos por diseño) (figura 1).
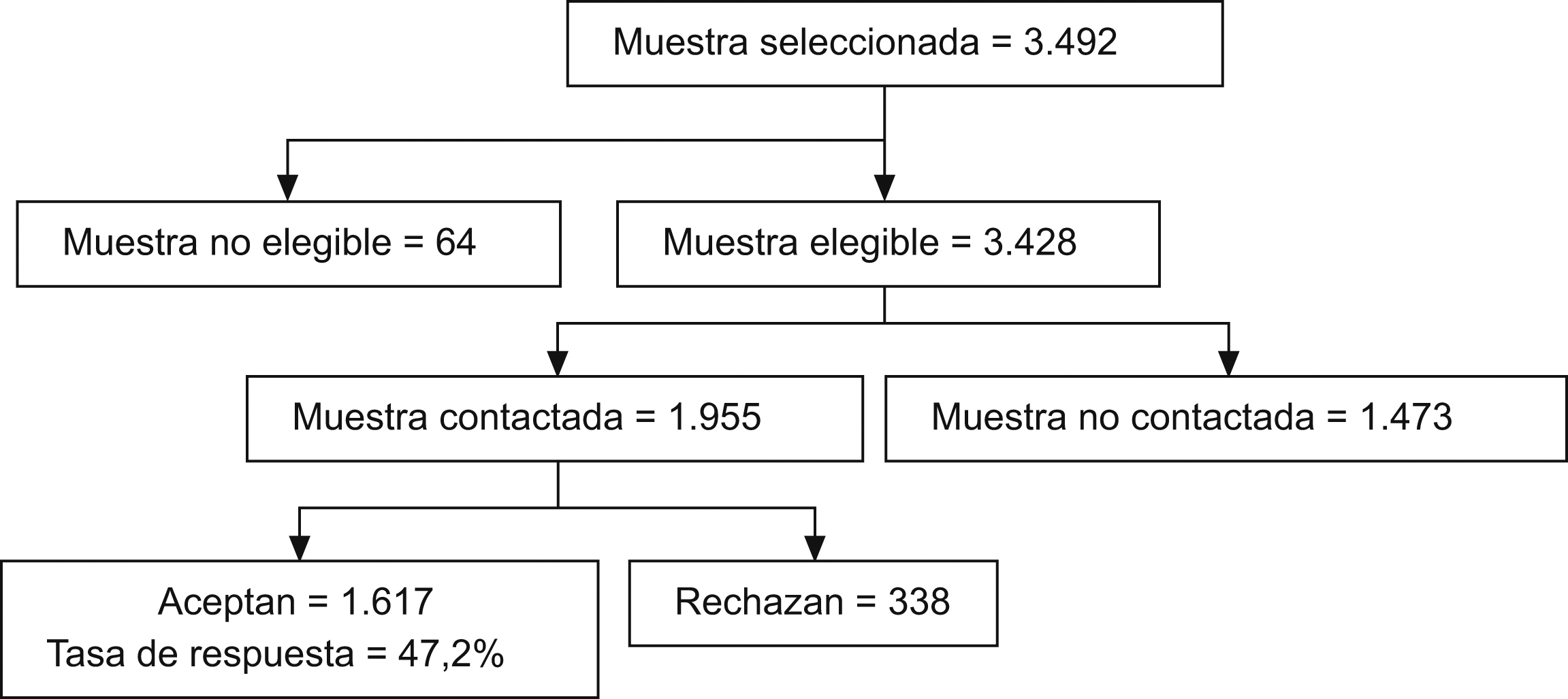
Figura 1. Flujograma de la tasa de respuesta a la Encuesta Nacional de Salud de Chile (2003).
La tabla 1 presenta algunas características demográficas de la muestra original elegible, los respondedores y los no respondedores. Los respondedores son en mayor proporción mujeres, de mayor edad, de nivel socioeconómico medio, menos activos laboralmente, con mayor prevalencia de enfermedad crónica declarada y menor prevalencia de tabaquismo. Tienen también peor salud autopercibida, con una diferencia estadísticamente significativa entre los menores de 45 años.
Tabla 1. Características seleccionadas de los sujetos de la muestra original, respondedores y no respondedores a la Encuesta Nacional de Salud de Chile (2003)
| Muestra original elegible (n=3.428) | Respondedores (n=1.617) | No respondedores (n=1.811) | |
| Sexo | |||
| Varón | 46,7% | 41,3% | 51,6% |
| Mujer | 53,3% | 58,7% | 48,4% b |
| Edad | |||
| 17–24 años | 13,1% | 12,3% | 13,9% |
| 25–44 años | 32,4% | 28,6% | 35,7% |
| 45–64 años | 31,7% | 32,4% | 31,0% |
| ≥65 años | 22,8% | 26,7% | 19,4% b |
| Nivel socioeconómico | |||
| Alto | 18,5% | 17,0% | 19,8% |
| Medio | 43,5% | 48,2% | 39,4% |
| Bajo | 38,0% | 34,8% | 40,9% b |
| Laboralmente activo | |||
| 17–44 años | 55,0% | 49,1% | 59,4% b |
| ≥45 años | 44,8% | 40,4% | 49,3% b |
| Salud autopercibida | |||
| 17–44 años | |||
| Mala | 4,2% | 5,2% | 3,5% |
| Regular | 17,4% | 19,3% | 16,0% |
| Buena | 78,5% | 75,6% | 80,6% a |
| ≥45 años | |||
| Mala | 12,8% | 13,7% | 11,8% |
| Regular | 28,2% | 29,5% | 26,8% |
| Buena | 59,0% | 56,8% | 61,4%NS |
| Alguna enfermedad crónica | |||
| 17–44 años | 24,7% | 29,6% | 21,2% b |
| ≥45 años | 62,6% | 65,1% | 60,0% a |
| Tabaquismo actual | |||
| 17–44 años | 46,7% | 46,8% | 46,7%NS |
| ≥45 años | 26,7% | 24,5% | 29,0% a |
Fuente: Encuesta Nacional de Calidad de Vida_2000.
Comparación de distribución de las variables entre respondedores y no respondedores mediante χ2 de Pearson.
NS: no significativo.
a p<0,05.
b p≤0,001.
En la tabla 2 se muestran los estratos creados basándose en quintiles de la propensión a responder, que presentaron tasas de respuesta crecientes, desde un 15% en el primero hasta un 82% en el quinto.
Tabla 2. Tamaño y tasa de respuesta observada en los estratos de ajuste construidos según la propensión a responder
| Estratos de ajuste | n | Tasa de respuesta |
| 1 | 685 | 14,6% |
| 2 | 687 | 32,3% |
| 3 | 685 | 46,4% |
| 4 | 685 | 60,9% |
| 5 | 686 | 81,6% |
| Total | 3.428 | 47,2% |
La distribución de las características sociodemográficas de la muestra de respondedores, tras la corrección por la propensión a responder, mostró una distribución similar a la de la muestra original por sexo y edad, excepto entre los menores de 24 años. También se obtuvo una corrección de la distribución del nivel socioeconómico, aunque levemente para el alto (tabla 3). Por diseño, la sustitución muestral corrige las distribuciones por sexo y edad, ya que éstos eran criterios para la selección de los sustitutos.
Tabla 3. Distribución de variables sociodemográficas en la muestra original (a), en los respondedores (b) corregidos (c) y sin corregir por la propensión a responder, y en la muestra con sustitutos (d) a
| Muestra original (a) | Respondedores (b) | Diferencia [a–b] | Respondedores corregidos (c) | Muestra con sustitutos b (d) | Diferencia [a–c] | Diferencia [a–d] | |
| Sexo | |||||||
| Varón | 49,0% | 44,0% | 5,0% | 49,8% | 48,9% | 0,8% | 0,1% |
| Mujer | 51,0% | 56,0% | 5,0% | 50,2% | 51,1% | 0,8% | 0,1% |
| Tramo edad | |||||||
| 17–24 años | 18,8% | 18,5% | 0,3% | 20,1% | 19,2% | 1,3% | 0,00% |
| 25–44 años | 43,4% | 40,4% | 3,0% | 42,3% | 45,3% | 1,1% | 0,20% |
| 45–64 años | 26,9% | 27,8% | 0,9% | 26,8% | 26,2% | 0,1% | 0,10% |
| ≥65 años | 10,9% | 13,3% | 2,4% | 10,8% | 9,3% | 0,1% | 0,00% |
| Nivel socioeconómico | |||||||
| Alto | 22,9% | 20,2% | 2,7% | 20,7% | ND | 2,2% | – |
| Medio | 48,9% | 54,2% | 5,3% | 49,2% | ND | 0,3% | – |
| Bajo | 28,2% | 25,5% | 2,7% | 30,1% | ND | 1,9% | – |
Fuente: Encuesta Nacional de Calidad de Vida _2000.
a Porcentajes calculados sobre las muestras expandidas para reflejar las distribuciones finales con que se realizan las estimaciones de prevalencia.
b No es posible comparar el nivel socioeconómico de la muestra con sustitutos, pues no se utilizó la misma metodología para su medición en la Encuesta Nacional de Salud que en la Encuesta Nacional de Calidad de Vida.
Al modelar la capacidad del modelo de propensión a responder (pˆ(x)) para predecir la presencia de enfermedad se observó que el coeficiente β de la regresión Y=β(pˆ(x)) resultó significativo para predecir seis de las siete enfermedades analizadas (exceptuando la enfermedad pulmonar obstructiva crónica [EPOC]) (tabla 4).
Tabla 4. Determinación del beneficio de utilizar el modelo de propensión a responder para corregir el sesgo de no respuesta en la prevalencia de siete problemas de salud, y efecto esperado del ajuste
| Problema de salud (Y) | Coeficiente de la regresión: logitE(Y)=β0+β1(PR) a | Efecto esperado del ajuste estadístico sobre las prevalencias |
| Hipertensión arterial | 0,27 b | Reducción |
| Diabetes mellitus | 0,11 b | Reducción |
| Depresión | 0,14 b | Reducción |
| Enfermedad pulmonar obstructiva crónica | 0,09NS | Elevación |
| Reflujo gastroesofágico | 0,21 b | Reducción |
| Obesidad | 0,36 b | Reducción |
| Tabaquismo actual | −0,29 b | Elevación |
NS: no significativo.
a Se ajustó una regresión para cada problema de salud (Y). PR es la propensión a responder estimada para cada sujeto. Un coeficiente β1 significativamente distinto de cero indica que el modelo de propensión a responder es adecuado para ajustar la prevalencia de ese problema de salud.
b p≤0,005.
En la tabla 5 se comparan los resultados del ajuste estadístico y la sustitución muestral con las prevalencias crudas. Para seis problemas de salud, ambos métodos modificaron las prevalencias en el mismo sentido. En hipertensión arterial y diabetes mellitus, ambos llegaron a la misma estimación; en depresión y reflujo gastroesofágico, la magnitud del ajuste estadístico fue mayor, en tanto que para obesidad fue mayor el ajuste mediante sustitución. En el caso del tabaquismo, el ajuste estadístico elevó la prevalencia en 2 puntos, en tanto que la sustitución muestral la redujo en 0,4. En la EPOC, ambos métodos ajustan en sentido contrario al esperado. Los intervalos de confianza de las estimaciones ajustadas estadísticamente son más amplios que los obtenidos mediante sustitución.
Tabla 5. Prevalencia de siete problemas de salud medidos en la Encuesta Nacional de Salud de Chile de 2003. Comparación de las estimaciones sin corregir, corregidas mediante propensión a responder y corregidas mediante sustitución muestral b
| Prevalencias sin corregir (IC95%) | Prevalencias corregidas por propensión a responder (IC95%) | Prevalencias corregidas por sustitución muestral (IC95%) | |
| Hipertensión arterial | 35,9% (32,4–39,6) | 33,9% (30,0–38,0) | 34,0% (31,5–36,5) |
| Diabetes mellitus a | 7,7% (6,2–9,4) | 6,6% (5,3–8,2) | 6,7% (5,8–7,8) |
| Depresión | 18,5% (15,7–21,7) | 15,8% (13,3–18,7) | 17,5% (15,5–19,8) |
| Enfermedad pulmonar obstructiva crónica | 22,6% (19,4–26,2) | 21,0% (17,8–24,7) | 21,7% (19,7–23,9) |
| Reflujo gastroesofágico | 31,8% (28,5–35,2) | 28,2% (24,6–32,0) | 29,9% (27,6–32,3) |
| Obesidad | 26,1% (23,0–29,4) | 25,3% (21,6–29,4) | 23,6% (21,5–25,7) |
| Tabaquismo actual | 42,9% (39,3–46,6) | 44,8% (40,6–49,1) | 42,5% (39,8–45,1) |
IC95%: intervalo de confianza del 95%.
a Prevalencias calculadas sobre las muestras expandidas.: glucemia en ayunas ≥126mg/dl9.
b Criterio de la American Diabetes Association (2003).
En este estudio se compararon dos procedimientos para corregir el posible sesgo de la no respuesta en los resultados de una encuesta poblacional de salud. Se han comparado las estimaciones de prevalencia crudas obtenidas de la encuesta con las estimaciones ajustadas mediante un factor de no respuesta basado en la propensión a responder. Éste modificó las estimaciones en el sentido esperado y en el mismo que la sustitución muestral semicontrolada efectuada durante el trabajo sobre el terreno. Si bien estas modificaciones fueron en general de mayor magnitud cuando se aplicó el factor de no respuesta, ambos métodos dieron resultados similares. Sólo en el caso del tabaquismo la sustitución muestral, y no el ajuste estadístico, dio resultados contrarios a los esperados. En un caso (EPOC), ambos métodos parecen haber sido inapropiados.
Si bien el sesgo de no respuesta está más asociado al rechazo que al no contacto24, y en la Encuesta Nacional de Salud de 2003 la mayor pérdida se produjo por no contacto, las diferencias observadas entre respondedores y no respondedores resultaron significativas. Los respondedores eran mayores y menos saludables que los no respondedores, lo que sugería que el sesgo de no respuesta aumentaría la prevalencia cruda de enfermedad y el efecto de la corrección debía ser su reducción, tal como se observó en el presente estudio. Entre los respondedores predominaba el nivel socioeconómico medio, lo que hizo que la muestra reclutada tuviera menor presencia de personas tanto de nivel alto como bajo, con lo cual el nivel socioeconómico debería tener poco efecto sobre las prevalencias crudas de enfermedad. Por último, los fumadores respondieron algo menos, con lo que se esperaban resultados crudos que subestimaran la prevalencia del tabaquismo.
En cuanto a la evaluación del modelo de propensión a responder utilizado, se observó que el ajuste basado en él restituyó la muestra a su estructura demográfica original en casi todas las variables analizadas. Sin embargo, aumentó la diferencia en los menores de 24 años, lo que refuerza la noción de que dichos ajustes podrían, en algunos casos, aumentar el sesgo, y por ende sería necesario evaluar su utilidad en ese grupo de edad. La evaluación del modelo mediante la regresión del propensity score como predictor de la presencia de enfermedad indicó que no sería adecuado utilizarlo para la EPOC, lo que parece confirmarse al obtener resultados contrarios a los esperados.
La comparación de ambos métodos de corrección del sesgo de no respuesta mostró resultados similares entre ellos, excepto para el tabaquismo. Además, ambos métodos produjeron modificaciones pequeñas con respecto a las prevalencias crudas. Esta semejanza de resultados entre dos métodos muy diferentes sugieren que el sesgo de no respuesta podría ser pequeño a pesar de la elevada tasa de no respuesta y de las diferencias observadas entre respondedores y no respondedores.
Estudios similares también han encontrado diferencias pequeñas entre los valores de prevalencia con y sin corregir22,25,26,27,28,29. Esto se podría explicar porque los atributos que diferencian a los respondedores de los no respondedores tienen efectos de sentido opuesto sobre las prevalencias27. Así, la prevalencia observada debería tender a aumentar por efecto de unos y a disminuir por efecto de otros.
Para algunos autores, esta modificación tan pequeña en las prevalencias corregidas sería producto de la falta de concordancia entre las variables predictoras de la respuesta y las variables predictoras de enfermedad27. Sin embargo, la propensión a responder estimada de cada sujeto resultó ser un predictor significativo de la probabilidad de estar enfermo para casi todas las enfermedades analizadas13.
En cuanto a la comparación de las técnicas, las diferencias en la magnitud de las correcciones podría deberse en parte a que la sustitución muestral reemplazó a toda la pérdida, independientemente de su elegibilidad. El 50% de los no elegibles eran mayores de 65 años que habían fallecido (n=32), cuya sustitución por sujetos de la misma edad podría elevar la prevalencia global de enfermedad. Sin embargo, éstos sólo representan el 3,5% de los mayores de 65 años de la muestra de la ENS_2003, y cabe recordar que, para estimar las prevalencias, ambas muestras son restituidas a la misma composición por sexo y edad, correspondiente a la población chilena proyectada para agosto de 2003. Otra explicación posible es que dado que los sustitutos son también respondedores, podrían presentar características similares a los respondedores de la muestra original11.
El tabaquismo es la única de las siete condiciones estudiadas en que la sustitución muestral, al contrario del ajuste estadístico, no modificó la prevalencia en el sentido esperado. Si bien en la ENS_2003 los sustitutos fueron definidos a priori, para evitar reclutar sólo a respondedores complacientes, en la medida en que la probabilidad de responder esté correlacionada con la condición en estudio, la sustitución muestral tenderá a mantener o incrementar el sesgo. Es así que en distintos países del mundo se ha descrito que los fumadores son no respondedores a encuestas de salud, especialmente a las de patología respiratoria30,31,32. En Santiago de Chile, el estudio Platino de prevalencia de enfermedades respiratorias crónicas en los mayores de 39 años aplicó un cuestionario abreviado a los no respondedores, y encontró que la tasa de no respuesta fue 1,3 veces mayor entre los fumadores33, relación idéntica a la observada en la ENS_2003 (datos no mostrados). Esta misma tendencia a no responder se daría entre los candidatos a sustitutos, lo que explicaría por qué en la muestra con sustitutos se obtuvo la misma prevalencia de tabaquismo que entre los respondedores.
Un posible aumento en la varianza de las estimaciones obtenidas mediante ajuste estadístico por este procedimiento fue descrito por Little13; sin embargo, en esta experiencia, los intervalos de confianza obtenidos son similares a los obtenidos sin corregir y no llegan a afectar la interpretación de los resultados.
Se debe tener en cuenta que así como la sustitución muestral selecciona respondedores (complacientes o no), el uso del propensity score se basa en supuestos que en la práctica no se cumplen totalmente. Así, se supone que se agrupa a los sujetos en estratos homogéneos en cuanto a su propensión a responder (todos los sujetos de un estrato tienen la misma probabilidad de responder), y por ende se obtienen estratos dentro de los cuales la no respuesta es al azar y no hay sesgo de no respuesta13. No obstante, en la práctica se trata de una probabilidad de respuesta estimada basándose en las covariables disponibles, por lo que no es posible trabajar con la probabilidad real de respuesta. Por otra parte, no se pueden construir estratos dentro de los cuales la propensión a responder sea totalmente homogénea sin incrementar exageradamente la varianza (gran número de estratos). Además, se debe tener en cuenta que, aunque se trata de un método sencillo que permite emplear una mayor cantidad de información de la que podría utilizarse para la adecuada selección de un sustituto9, en muchas ocasiones no se cuenta con la información necesaria para efectuar una corrección basada en la propensión a responder.
Un punto que ha quedado sin resolver en este trabajo es la identificación de la información mínima necesaria para realizar un adecuado ajuste estadístico, idealmente que pueda ser recogida sobre el terreno cuando no existe información de base. Sin embargo, ensayos con diferentes modelos de propensión a responder no han obtenido resultados sustancialmente diferentes para los diversos modelos15. Queda también por analizar si la sustitución muestral es igualmente capaz de corregir la no respuesta cuando hay mayor libertad para seleccionar a los sustitutos.
Ambas técnicas de ajuste del sesgo de no respuesta, la sustitución muestral semicontrolada y el ajuste por un factor de no respuesta basado en la propensión a responder, dieron resultados similares. La sustitución muestral semicontrolada mostró estimaciones más precisas (intervalos de confianza más estrechos), pero es un procedimiento más costoso en el trabajo de campo. La corrección mediante la propensión a responder requiere disponer de información sobre los no respondedores o elaborar un protocolo para recogerla, y además es un procedimiento menos transparente para el lector no experto, pero supone menos costes económicos y una menor duración del trabajo de campo.
FinanciaciónAlejandra Vives recibió financiación de los fondos para Proyectos de Investigación de Becarios Residentes de la Escuela de Medicina – 2003, de la Pontificia Universidad Católica de Chile, proyecto PG-20/03, para la primera etapa de este proyecto de investigación.
Recibido 27 Septiembre 2007
Aceptado 21 Enero 2009
Autor para correspondencia. alvives@med.puc.cl











